
CVS Model for AI Vision:
Neuromodulation inspired concept for Recognition and Classification of the visual Field.
This article is a direct follow-up on a larger investigation towards understanding the act of seeing, as a process of collapsing a field of ambiguity into meaning. The core of this spesific article, swarms around the possibility of transforming collapse-verify-stamp as computational and practical frame for AI vision.Before i move further into the topic itself, I recommend taking a look at the original foundation from which these ideas compound. You can access the Visual Logic Framework directly from here.WHAT IT MEANS TO SEE
To simplify the complexity of what it means to “see”, we must first establish a common ground to tread on.
Seeing means different things depending on which field is observing it.
Science, philosophy, art, education and technology all value and treat the concept differently.
As a matter of fact, in many cases, these fields disagree on a large variety of fundamental issues.
This article, hopefully provides clarity, showing that there are far more agreements beneath the surface than actual conflicts.
The foundation for the CVS model (collapse-verify-stamp), and for what will be proposed here, is grounded in a history of scientific discoveries, technological applications and artistic methods, which are explored in my other articles.
This compressed principle of CVS is an attempt to transpose what can be applied from the biological model- the human aspect of vision-into an artificial form.
Following the tradition of my prior articles, we don’t start with numbers, we start with a question: If ambiguity becomes resolved, it has to be attended. How does the information flow that vision is built from?
WHAT CAN BE SEEN?
EXTRACTION OF INFORMATION IN VISUALS
1. Light interaction with the environmentAs I have mentioned before with my articles, light interacts with the environment.
To dive slightly deeper into that, we can simplify this stage thru physics alone.
Light is energy, and as photons encounter matter, they interact with it.
Depending on the matter itself, reactions happen on different scales.
For example:
Energy is converted to heat.
If you have ever worn a black shirt on a sunny warm day, you have noticed that your shirt gets hot.
What happens in reality is that dark or black matter doesn’t reflect much light; it absorbs it.
The energy that the light carries doesn’t disappear - it converts to heat.
Every color and shade that you perceive is what is left over from these interactions.
Everything that light touches becomes a mathematical equation and is entirely predictable, since materials nearly always react to it in the exact same way under specific conditions .
Think of them as fingerprints.
That is how we recognize and differentiate that metal, glass, organic fibers or stone, all have different appearances.
Humans do not measure or calculate all possibilities; we extract only the ones within specific range.
2. LIght within human sensory thresholdsLike mentioned, our brains don’t need to compute the world or calculate numbers to learn to recognize these differences.
Biology developed the perfect precision tools for the job.
As reflected light (the remining energy after environmental interactions) enters our eyes, receptors in our retinas don’t react to full scalar spectrum, but to specific ranges of wavelengths.
Depending on the luminance of the light sources (the exposure level), an adaptive threshold is applied.
The pupil opens or retracts to capture the optimal ratio.
These thresholds create a sensory scalar that adjusts to conditions, stripping away excess noise and filtering the stimuli.
We see different data in the dark than we see in the light.
Adaptive thresholds can be observed with a simple test when different visual values are introduced against varying background exposure levels.
Between two absolute exposure levels, our perception of the values changes.
In one scenario, we might not be able to effectively distuinguish differences in group A or B - the values appear nearly identical at first glance, however, in group C, we are able to read the differences more clearly.
If we change the exposure level to the opposite end of the spectrum, the phenomenon flips: now the differences in Group A are clear, while Group C and B appear to have more identical values inside of them.
If we shift the exposure level live, the dots appear animated, and in a way they are.
As the background intensity crosses these thresholds and becomes a match, one at a time dot disappears into the corresponding value.
That is how fast our eyes adjust to conditions.
Relative Value Groupings (Global Exposure)
Move the slider to change the global room exposure. Notice how your perception of the fixed dot groups changes entirely based on the single ambient background.
The RGB values of the dots are physically locked. Only the global background container is changing.
This function of sensory differences is known as the Weber-Fechner law, which describes what is known as the JND (Just Noticeable Difference).
It is the biological foundation from which image editing concepts, such as contrast and value thresholds derive from, though the technical applications itself are not directly reflecting that.
The conditions of appearance is determined by Energy interaction (the field of possibilities) filtered thru Sensory thresholds.
This establishes the foundation - a puzzle for the brain to solve.
S = E / sensory_threshold > What can be seen.
WHAT IS SEEN?
Human brains don’t recompute the entire visual field and solve the puzzle frame-by-frame.
The brain predicts based on priors, which include the memorization of patterns, expectations and neural reactions.
We could think of this as going to a massive library.
The first time you visit, the sheer amount of shelves, books and different categories makes the experience overwhelming when you are trying to search for a specific book.
Some people might begin to explore what they can find, some use the terminals to locate a section.
And some seek help from the librarians.
The more times you visit, the less complex it becomes.
If you worked there as a librarian, navigating the space is obvious and routine.
This isn’t about the absolute memorization of every single item; it is pattern-based.
If the library gets renovated - even if every shelf, book and category remains identical, and only the physical placement of the shelves is changed - it will require relearning even for the professionals.
Muscle memory works in similar way.
You learn to ride a bicycle, and it becomes automated function, what we refer to as a learned skill.
In visuals, this is known as pattern recognition.
As our visual systems develop and our ability to extract information from our surroundings improves, we slowly begin memorizing what the information represents.
This is where the “energy fingerprints” play a significant role.
We quite often take it for granted, and don’t acknowledge how big of an impact visual patterns have on our sense of reality.
This might be due to an early developmental stage known as infant amnesia.
We simply do not remember the first time we saw a mirror, or an object that was yellow.
As far as we remember, we have always known what metal is - and not just metal, but different types of metal.
We know what glass is, and the amount of refraction it creates, even if we don’t possess teh vocabulary to explain what “refraction” means.
We actively recognize patterns until they become learned and consolidated.
But there is no actual “hard drive” or memory bank where the raw visual data is stored.
It is a learned attention mechanism.
The question then becomes: How are cognitive resources distributed within this learning mechanism?
After all, if we just randomly selected data, or tried to process everything in our visual filed at once, it would overwhelm our neural processing. How do we know what, and when to select?
TWO OPPOSING FORCES OF CLASSIFICATION
Most of us have memory of the funny mirrors at amusement parks.
When you look at yourself in one, it creates a distorted reflection.
We hold that in our memory likely because it is quite rare.
But as I have watched all three of my kids grow up, they all went thru a period where a regular mirror was the most fascinating thing in the world to play with.
When something grabs our attention this way, we focus on it naturally.
We study it, we play with it and we stare at it.
More importantly, we engage with it.
We think about it from several perspectives.
How does it work, and imagine the possibilities we could use it for.
Throughout your life, every time you saw something for the first time, it triggered this exact same process.
Every material was once ambigious and extraordinary to you.
Look at toddlers: They play with rocks, sand, grass, sticks, mud and water.
That is how you familiarized and trained your attention mechanism to recognize everything you see today.
But there was a time when those were all anomalies, and playing with them allowed you to be surprised from the discoveries that followed that play.
The assumption among the general population regarding neuromodulators (like dopamine) swirls around the idea that it is a “reward” mechanism - something that gives us a good feeling when we get things right.
But in fact, dopamine plays a much more mechanical role in that cascade.
Science dictates that neurons either fire, or they fall silent.
There are no backwards firing mechanics, but a dip below baseline can itself carry the negative signal.
These firing neurons cause chemical reactions that we identifie as feelings or emotions thru complex nervous system that is entangled all the way.
So there are far more connections than is presented here, but when it comes to looking at it from the stand point of playing a role within CVS model, we will focus on one key quality.
Dopamine itself fires on surprise events.
What is considered a surprise is generally an anomalous event - something that does not fit into our current expectation or prediction of the environment.
It is a signal that alters our attentional awareness, and by doing so, forcing us to learn.
The outcome of that event then gets possibly classified.
If we simplify the concept, when an outcome is stable, expected or succesfully verified, and is consolidated, serotonin steps in.
Serotonin stablizes the network, acting as the counterpart to dopamine’s exploratory push.
Many of the medications used to affect these reactions, are traditionally supressors.
Despite the common thought that one is adding “more” of a substance to feel better, the medication is often used to supress an overactive firing mechanism.
Like using a fire extinguisher on a system that is burning too hot.
This stage of learning Attention can be formalized as:
A = S x pattern_weights > What is seen.
FROM AMBIGUITY TO MEANING
Now that the foundations of seeing and recognizing the visual field are set, we arrive at the final step of the collapse-verify-stamp cascade.
Patterns themselves are not memories - at least, not in the way humans consciously define them. People rarely ask, “Do you remember my coffee machine?” without a reason.
If an object wasn’t related to a specific event, or if it wasn’t visually anomalous, our brains reject it as a candidate for long-term memory.
If there is no context around it and it never triggered an anomaly, we simply do not find it meaningful enough to store.
Our concept of memories is based on events, not “things”.
They are lived experiences.
We remember emotional states and moods that, in context, are tied to sounds, smells, feelings, tastes or visuals - either individually or combined across our senses.
We all have had experiences that seem to move us backward thru time.
A specific smell might instantly transport you to a childhood moment you thought you had forgotten.
Our sensory system is exceptional in this way.
It doesn’t store things long-term simply because they are visual anomalies; it stores them because the full experience was exceptional and attended.
It assigns a salience value that carries personal meaning, perhaps to you only.
Another example is when we try to learn a new skill. Usually, this requires persistence thru several failures.
Based on our track record, our expectation is failure, and more importantly, we consciously recognize that failure.
Once we finally succeed, our system reacts powerfully.
That success triggers a massive spike and gets pushed as a candidate for long-term memory.
But the key is what happens next: when you succeed the next time, it will not cause that same massive reaction.
Your expectation switches fast.
Once you know you can do it, failing actually causes you to feel regret much more dramatically.
As we continue succeeding, the skill becomes more and more routine, until it is so obvious that we do not react to it at all.
You will probably always remember one or two of those early successes, but most of them fade into automation.
In a similar way, our visual field becomes obvious.
What gets chosen - what gets collapsed from the field of possibilities - will be based on fingerprints, familiarity, context, expectations or anomalies.
It is entirely meaning-driven.
To now tie this as structural component for vision, the core of CVS would become:
E=energy
S=sensory
A=attention
M=meaning
S = E / sensory_threshold > What can be seen
A = S x pattern_weights > What is seen
M = A x memory_context > What has meaning
Each creating a multiplicative gate that doesn’t excessively recompute everything, only based on what passed thru the prior.
IMPLICATION
The original Biovision architecture, which was conceptually experimented on in Visual Logic Framework, has now been practically developed thru this CVS concept using 3D data and classification.
The current stage of the model’s architecture was initiallly tested and trained on ModelNet40, where it achieved test accuracy of 90.98%.
Further development is currently underway on ScanObjectNN’s hardest variant (PB_T50_RS), where it has recently pushed past 81% accuracy threshold running on consumer grade NVIDIA RTX 4070 ti ventus with 16GB RAM DDR5 Fury Beast - moving beyond historical baselines such as Pointnet++ and DGCNN, into the realm of heavily optimized data center architectures.
More about the explicit development stages and the performance will follow shortly in the near future.
The technical translation of this biological model into code has been more than revealing insight of how many variables move the gradients.
If you managed to read all the way thru, I would like to thank you for taking the time to do so.
It seems that in today’s era, there will be much less real readers and more crawlers doing the reading for you.
Sincerely
Mikko
note/ some graphics and other will be added shortly to accompanie this article, just my weird habit of adding those visual ingredients as update rather than doing all at once.
Visual Logic: From collapse to meaning
A cross-disciplinary framework exploring perception as a biological imperative, revealing how collapse, verification, and meaning form the architecture of seeing across human and artificial systems.
The Architecture of seeing as an act of construction
Cross-disciplinary investigation on perception, imagination and neuroarchitecture.
This article is a personal thesis and argues that perception is a biological imperative to collapse ambiguity into meaning. By weaving together neuroscience, psychology, and computation, we can expose the architecture of seeing. Revealing how this same process shapes imagination, constructs reality in the eyes of neurodiverse minds, and reveals why artificial systems do not see like we do.CONTENT:
The act of seeing
> What it means to see as a cognitive process, perception as construction.
The Biological truth
> Visual pathways, M/P distinction, anatomy, and grounding in real biology.
Collapse Model
> Collapse-Verify-Stamp process: perception as timing and negotiation.
Timing dynamics in perception
> Where stability, noise, and delay shape what we consciously “see”.
Conditions of existence
> From seeing-appearance-existence; perception as conditional emergence.
Creativity as natural play
> How imagination, intuition, and System 1/2 connect to learning and flow.
Experiment
> Drawing task - hunt for CVS.
Education and visual perception
> How visual logic translates into teaching and art.
Artificial perception and AI vision
> 3D and Ai vision-based task problems.
The Biovision prototype
> AI model inspired by CVS timing architecture. Results and charts.
Biovision’s stabilizing system
> Implications of perception, results and charts.
Conclusions and open questions
> Summarize findings, limits and next directions for science and art.
WHAT DOES IT MEAN TO SEE?
Camera does not know it is looking, a neural network, no matter how deep, does not flinch at beauty or get distracted in chaos. Yet, in the age of machine learning we keep saying it:
"The AI sees"
Today´s artificial systems can receive light thru lenses.
They can extract data from pixels, detect edges and identify objects often faster and more precisely than we can.
But does that mean they see?
To ask this question seriously, we must first return to a deeper understanding of what seeing truly is.
Not from a standpoint of sensors or computational process, but from the lived reality of perception itself.
When a human being sees, we do not simply gather visual data.
We collapse a field of ambiguity into something meaningful.
We predict and interpret. Much like a boxer slipping a punch, or when something falls from the table suddenly, and in a blink of an eye you manage to grab it.
Even though you weren´t prepared for it.
Or were you?
Our perception is not passive input. It is a generative act.
It gathers and turns scattered photons into form, memory and experience.
This article is an inquiry of that action.
It explores how we, as biological observers construct visual meaning into reality.
Along the way, we will confront some difficult truths:
That form is not fixed, that reality shifts depending on who observes it, and that perception itself is
conditional, layered and creative.
At the heart of this investigation, is a framework that i call Visual Logic .
Practice that helps reveal how we build our sense of reality.
It isn´t merely a tool for artists. It´s a tool for anyone who want´s to understand what truly happens in the moment we say, "I see".
And so we begin: - not with a machine, but with a question:
"If seeing is the act of collapsing reality into a meaning, then what does it take to see at all ?"
RECONNECTING ART AND SCIENCE
Optics unified physics and art thru perspective and light.
As a proof of this cross-disciplanary system, I present my timelapse article -
From Newtons prism, thru the foundational research of human role as the observer by Weber-Fechner. From Young`s trichromacy straight to Maxwells electromagnetic theory, and into modern technology and development.
Visual Logic proposes that this shared origin can be rebuilt, specially now that AI and rendering technologies are forcing that reconvergeance.
If Visual Logic can be taught to children and simultaneously inspire academic research or tool development, it is not theoretical - it´s functional and foundational.
" What are the underlying constraints that both, computational systems and humans, must obey to produce belivable visual outputs ?"
WE ARE THE BRIDGE - THE HUMAN ACT OF SEEING
We tend to belive that seeing is passive, a camera-like process that simply records what is already there.
But this belief is not only false - it blinds us to what seeing truly is.
To see, is not to receive.
To see is to collapse from possibilities into a meaning of what we call "visual reality".
It is an active resolution, shaped by our biology, memory and cognitive status.
The deep architecture of the mind.
Every moment you open your eyes, your brain performs a miracle synthesis, dynamic computation.
Let´s take a look at it.
BIOLOGICAL TRUTH - The Feedforward/Feedback loop
Visual information travels from retina to the primary visual cortex (V1) in under 60 milliseconds.
It sweeps thru the ventral visual stream (V2-V4-IT Cortex) where object identity and meaning are determined.
Then almost immediately feedback loops return to early visual areas to refine the initial suggestion.
Biologically our act of seeing begins before we are even aware of it.
Retinal ganglion cells do not simply forward light signals to the brain.
They actively compress, predict and select which signals pass forward.
This feedforward mechanism represents a structural "collapse" of the infinite possible visual fields into a single plausible percept.
By the time the signal reaches higher cortical areas, System2 can only witness and interpret what has already been chosen.
Yes, System2 .
This is not philosophical suggestion but a biological necessity:
Our perception is not passive recording - it is an active, continuous act of collapse that is orchestrated by our nervous system before conscious thought begins.
DUAL SYSTEM
Retina contains 20-40 subtypes of ganglion cells, each extracting distinct visual features at different speeds.
They forward these thru pathways that are part of two independent streams known as dorsal and ventral streams.
This dual system creates a possibility to bypass crucial information to be processed, collapsed faster.
System1 being the quick and dirty channel of Magnocellular pathway- part of the dorsal stream that invokes our spatial awareness.
This allows M-cell and DSGG input in rapid speed, to have ability to bypass primary visual cortex into superior colliculus that is responsible for unconscious vision.
It forms fast suggestions of meaning based on “where something is”.
For example:
Cup falls from table and you manage to grab it before it hits the floor.
Before a thought emerged, you reacted physically.
System2 is slow paced Parvocellular pathway, delivering higher resolution with fine details of color and texture.
Part of Ventral stream responsible for object recognition.
It carries visual information from P- and K-cells that leads into resolution of " what is ".
It fullfills the initial suggestions of Magnocellular system1.
For example:
You walk in a forest and see a snake on the ground.
Subconscious stream of information thru amygdala makes you react fast and jump back.
You look at the snake again, and now you recognise it is just a stick.
But you didn´t see the snake first.
There were multiple options in your sight to see.
Which to look at ?
In milliseconds, your brain chooses the most plausible interpretation- not based on the image alone,
but on what you expect, fear or assume.
It finds a meaning.
The chosen possibility becomes "what you see".
In this act of choosing, your brain does not simply see - it decides what you see.
This would suggest that the brain isnt´t waiting to "see".
It is running predictions, and recognizing when the incoming data matches an internal model.
This is not just speed, it`s evidence of layered cognition.
Brain uses visual input like a key to unlock prior patterns.
That´s a form of predictive coding, that was presented by Karl Friston- and it means that vision is a form of thinking ahead.
Not about capturing the world, it`s about resolving the most likely structure from incomplete fragments.
I hate to repeat myself, but
VISION IS NOT A RECORDING, IT´S A COMMITMENT.
Donald Hoffman`s interface theory of perception suggests that our senses evolved to present adaptive, useful "interfaces" , rather than true representations of objective reality.
Imaging studies showing task-dependent visual cortex activation, contextual "filling in", and dynamic percept switches support this view, hihglighting that perception is fundamentally a guided construction.
Visual Logic extends this principle:
Perception is not merely an interface but an active collapse into meaning.
We don´t see what is - we see what survives the collapse, chosen by our system to be coherent and
actionable.
In RSVP (Rapid Serial Visual Presentation) experiments, participants are shown images as fast as 13ms per frame.
Mary Potter´s RSVP experiments show that humans can extract the gist of an image already in that time,suggesting an ultra-fast, pre-conscious processing stage.
fMRI studies confirm early cortical activation (V1-V3,LOC) during these rapid presentations,
supporting a feedforward sweep that builds a preliminary, global meaning before detailed analysis.
This fits directly with Visual Logic´s dual-system collapse model : initial fast magnocellular-driven "collapse" to suggestion, followed by slow Parvocellular "verification" that solidifies conscious object recognition.
RSVP thus provides both behavioral and neural evidence for the staged, active construction of visual reality and memory.
Experiments with ambigious images - like the famous "duck/rabbit illusion"-people switch between two perceptions.
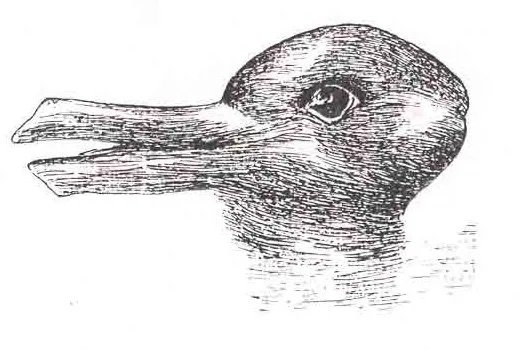
The image itself never changes, but what is seen collapses differently depending on observers attention or mood.
This is not a failure of vision, it is the nature of it:
To select one interpretation from many.
What you perceive isn`t simply what hits your retina - its what makes semantic sense with your layered cognitive filters.
In street scene studies, people are shown blurry, low resolution images.
They are still able to identify objects like stop signs, faces or vehicles.
But only if they are in context.
Remove the context and recognition plummets.
RSVP and ambigious image studies reveal that rapid visual recognition only occurs when the stimulus holds immediate, meaningfull significance to the observer ( such as faces or threat-related scenes).
In context-free or degraded images, perception fails to resolve without supporting meaning.
Demonstrating that the act of seeing is not simply a fast feature scan, but an active meaning-driven collapse.
We do not build a complete image and then recognize it.
We recognize, and the image is built on that anchor.
This evidence strongly supports Visual Logic:
Without meaning, there is no collapse -
and without collapse, there is no perceptual reality.
At least not a conscious one.
This staged commitment forms the basis of Visual Logic´s "collapse - verify" model, where rapid initial collapse offers a usable hypothesis, and slower verification confirms or refines it into
conscious reality.
COLLAPSE MODEL
Despite the philosophical nature of my question: What is the act of seeing, it is highly mechanical system-like operation.
And my proposal here holds more water than you suddenly might think.
David Marr´s seminal computation theory of vision proposed that perception unfolds in hierarchial stages:
First, a rapid edge-based representation, followed by a "2.5D sketch".
Describing Surface orientation and depth relative to the observer, and finally a full object centered
3D model.
Recent fMRI studies confirm this architecture at the neural level.
Early visual areas (V1,V2) detect edges and local contrasts, while dorsal stream regions (such as V3A and MT+) process surface geometry and depth matching Marr´s 2.5D sketch stage.
Higher ventral areas (LOC and inferotemporal cortex) resolve detailed object identity, completing the final percept.
Additionally, feedback signals from object recognition regions to early visual cortex ( as shown in Muckli et al 2015), support an active, iterative process rather than a purely feedforward pipeline.
This biological evidence aligns directly with Visual Logic´s collapse - verify model :
Fast, spatial "collapse" to initial Surface suggestions.
Followed by a slower, detailed "verification" of object meaning.
Seeing thus emerges not as a passive reception of images, but as an active construction of reality.
We can think of this model as a continuous collapse - not a single event, but rapid, ongoing series unfolding with each micro-movement of the eyes.
Every time we see, uncounscious actions begin in rapid motion.
Extraction of data, as you shift your sight thru all the possibilities that appear, recognition happens constantly,until one is selected. Commitment, followed immediately by suggestion thru the pipeline to be either endorsed or discarded.
The action is almost like refreshing frame -BOOM- here comes another image suggestion.
This is how you are able to spot familiar face in a crowd. Or how to find your keys from a messy table.
But it isn´t simply about creating an visual image, it is about forming conscious reality itself.
Magnocellular pathway is not merely choosing random stuff to propose, It selects things to create spatial awareness.
Conditions of existence.
COLLAPSE - VERIFY
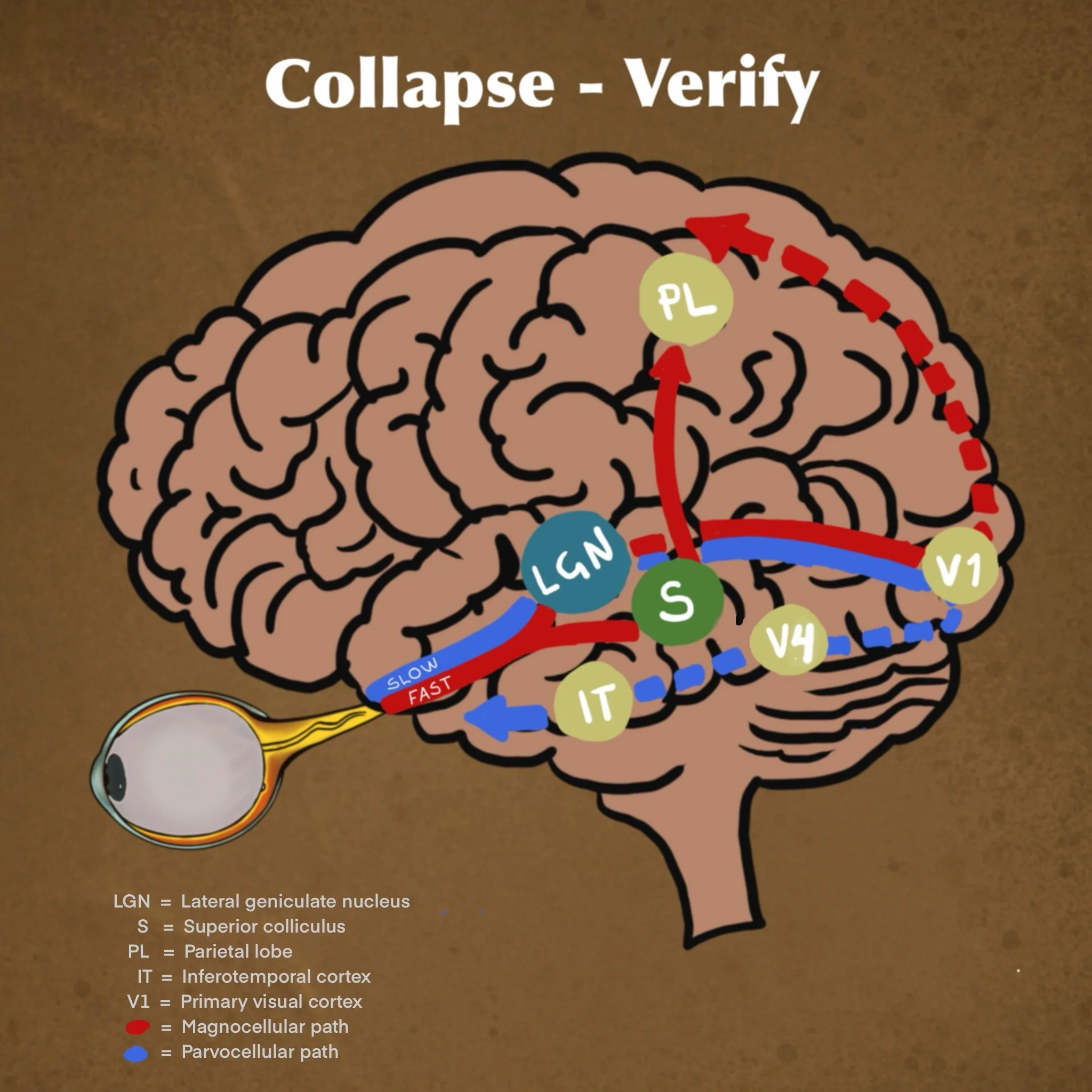
Sys1 (collapse) = Magnocellular pathway that is Fast and Dirty
What it gets:
M-cell input ( 30 - 50ms) Motion, shadows, contrast, flicker
DSGG input ( 20 - 40ms) Local directional movement
Collapse
Rapid thalamic bypass --> amygdala and dorsal stream
- Guesses meaning from sparse data
- Explains rapid attentional capture such as noticing movement before details.
Sys2 (verify) = Parvocellular pathway that is Slow, High Fidelity
What it gets:
P-cell input ( 50-100ms) Color,detail,high res.textures
K-cell input ( 40-80ms) Blue/yellow contrast, mood, attention
Verifies
- Receives sys1 collapsed output and delayed data to fill in the gaps.
- Either endorses - yes,it´s a face or challenges - wait, that`s a mask.
The third pathway, Koniocellular (K) , carries speacialized inputs from ganglion cell subtypes like the DSGCs. Despite traveling via the K-path, this information is ultimately distributed, “filling in” critical components for both the M-dominant Dorsal stream, and P-dominant Ventral stream.
INTERNAL OBSERVER
The act of seeing is not limited to external input.
Human beings are capable to reconstruct vision thru internal output, reconstructing vision this way is what we refer as:
Dreaming
Imagination
Hallucination
1. DREAMING
To the brain, it is still very much the same act of seeing.
Our visual system is activated mechanically similar way, than it is with our eyes open.
M-path and P-path actions are which separates and determines what the reconstruction is described as.
While there are no spesific researches made for Magnocellular activity in Dreaming- existing evidence suggests to that direction.
During REM sleep, the primary visual cortex (V1) is less active, but higher visual areas (MT/V5,parietal cortex)- which rely on M-input-remain engaged.
The thalamus(LGN) gates sensory input during sleep, and M-cells may be more resistant to suppression than P-cells.
Since P-path is mostly silent, our dreams involve more movement but with lesser details.
You have Felt the collapse - when you start waking up from a dream, there is a brief moment when you are confused what is real.
Until the verification kicks in.
2. IMAGINATION
During imagination at wake state, we are able to create reconstructed visuals with high detail, indicating that verification is involved in the process.
Pearson et al.(2015) research suggests that high-detail visual imagery activates P-pathway-linked regions.
Kosslyn et al.(2006) found that imagining moving objects activates M-Pathway-linked areas (MT/V5), suggesting that motion imagination relies more on M-like processing.
And further, recent fMRI studies by neurologist Adam Zeman and colleagues provide a striking support for this.
They discovered that when people vividly imagine an object, early visual corticies(V1,V2) activate almost as if they were actually seeing it.
This suggests that imagination is not simply a passive replay or symbolic thought - it is an active perceptual construction, internally performed by the same pathways we use to process real visual reality.
In individuals without mental imagery (aphantasia), this activation is absent, confirming the necessity of this internal collapse mechanism.
Zeman et al.(2020) reported that some aphantasics retain spatial navigation skills ( M-Pathway function), despite lackin visual imagery. My Interview with aphantasiac tattoo artist, confirms this in fascinating way.
fMRI showed reduced activation in ventral visual stream (P-pathway) but intact dorsal stream (M-pathway).
Keough & Pearson (2018) found that aphantasics perform poorly on high-detail imagery tasks (P-Pathway-dependent), but preserve spatial/coarse imagery (M-Pathway-linked) and Jacobs et al.(2023) suggests that some aphantasics use spatial/movement- based strategies (M-Pathway-like) to compensate for lack of imagery.
And Bainbridge et al.(2021) further supports the idea that P-pathway imagery generation is impaired, while perception remains intact.
Aphantasics could recognize objects (P-pathway task) but not reconstruct them mentally.
CASE STUDY : The aphantasiac tattoo artist
Interview with Jesse Sampo, a professional tattoo artist with aphantasia, provides a case study that vividly demonstrates the discussion between the M-pathway’s spatial reasoning and the P-pathway’s visual imagery. His experiences align with the scientific model and offer unique insights into the construction of visual art without internal imagery.
Grasping shape, Not image:
When discussing about visual imagination, Jesse’s description shows the core definition of difference between where (M) vs. what (P).
“ If I try to imagine a red apple in my head, well I could somehow grasp the shape of the apple but I couldn’t form any kind of colored image of it in my mind. “
He has the structural, spatial understanding ( M-pathway “collapse” of form and volume) but lacks the sensory, detailed visual imagery (P-pathway “verification” of color and texture)
Spatial memory without visuals:
As we spoke about “flashbacks”, memory based images and whether or not he experiences such, proves that it is not a memory deficit:
“ I do get memory images, and very precise ones too, but they aren’t really pictures, they’re more related to space. I remember where everything was located and what was in the space or room. You could say that it is more of a spatial memory, but in no case a so-called photograph.”
And further when discussing about memorizing visuals:
“ A good example when we were kids and in a cabin. Later as an adult, I was able to find that place with Google maps. I remember how you went to the shore. There was a long dock and it was next to the boat shed. Then there was a smoke sauna a bit further away. I also remember how they are located.”
Building art thru construction, not reproduction:
We then moved on to discuss how he approaches designing and creating art in general, and is he able to draw without models or refences:
“Skulls are one thing I can do really quickly, but that’s also such a learned thing. I need to build the shapes first before I can add the details to it… it’s just messy scribbles at first and only at some point does the idea of what I’m making start to form me.”
Jesse doesn’t see the skull in his mind and then draw it. He constructs it thru an iterative process of building shapes. This mirrors the biological “collapse-verify” process, where the “unclear scribbles” are his Sys1 making fast, dirty “collapse” to a form, which he then refines (verifies) with details.
The necessity of an anchor:
Challenge of verbal description becomes clear when Jesse works with customer wishes.
“Well for example: If a client writes to me that they want a misty castle, for me it’s just text that says misty castle. I can’t develop an image in my head of what it looks like. But the more and more detailed the description is and the clearer it is… even just a stick figure drawing is enough.”
This perfectly illustrates that without visual or structural anchor ( “collapse”), pure language is just data, not meaning.
The stick figure drawing provides a spatial anchor that allows him to begin the construction process.
When it comes to reading, Jesse explains what type of books he can read, and which turn out to be a nightmare:
“Madventures books are pretty much the only ones I’ve been able to read, it’s dialogue so I can imagine the events in my head with Riku’s or Tunna’s voice.”
But books like Game of thrones or Harry Potter, that include a lot of descriptions of items become almost impossible:
“ On one page there was something about a sword, and I must have read that page three times before I went to Google search to see what the sword looks like.”
3.HALLUCINATIONS
Hallucinations are strongly connected to these pathways, and indicate an impairment and dysfunction.
Schizophrenia patients who have M-pathway deficits report disorganized,less vivid dreams.Revonsuo et al.(2015)
This suggests intact M-pathway is needed for coherent dream spatial narratives.
Hub et al. (2004) Patients with M-pathway deficits (common in schizophrenia) show poor spatial imagination, but intesified and disorganized mental imaginery.
Carhart-Harris et al.(2014) LSD and visual processing- reported that LSD suppresses P-pathway
filtering, leading to M-dominant hallucinations. (swirling colors, motion trails)
Similar to dream visuals, supporting M-pathway dominance in altered states.
Charles Bonnet syndrome, that is a condition where visually impaired persons experience complex visual hallucinations due to loss of sensory input, researches are pointing towards M and P pathways.
fMRI studies show hyperactivity in cortical color-processing areas.
ffytche et al (1998) fMRI study showed distinct activation patterns correlating with the type of hallucination.
Ozer et al.(2020) found hyperactivity between (LGN),P-pathway and Superior colliculus, M-pathway.
This supports the proposal of dual system dysfuntions.
The M-driven Sys1 is fundamentally, not a passive receiver, but and active force of collapse.
Constantly seeking to condense sensory possibilities into a usable percept.
When collapse is delayed, incomplete or impossible (as in certain forms of blindness,scotomas or dysfunctions), Sys1 enters a state of desperation.
It continues to guess and collapse even when it is missing input.
This could explain phantom percepts.
Sys1 insistence on collapsing possibilities into coherent reality, underscores that perception is not just mapping,
it is biologically driven act towards resolution.
In the rare Riddoch syndrome, where (V1) is partially injured,patients can detect motion,(M-pathway)
but they cannot perceive static forms,indicating intact collapse but disabled verification.
When collapse(M) fails, initial perception is lost.
When verification fails (P), the system sees forms without knowing what they are.
In blindness, (V1) is known to be reassigned partially to process information from hearing and touch.
The only two senses after visuals, that are able to be used to create a sense of spatial awareness.
It seems to be, that our visuals are not simply there to construct an image of "what" lies ahead, but fundamentally to understand "where" we are in relation to the "what".
Without this drive, our coherent world experience would vanish into noise.
IT`S A RIGGED RACE WHERE TIMING BEATS CALCULATION
Perception is not a passive code running in the dark or simple hierarchy - it`s a rigged race who gets to place their pieces of the puzzle first.
Sys1 wins by default, and the slower Sys2 will verify or veto.
But what if Sys2 gets there first?
Or at the same time, interfering Sys1?
“When timing breaks down, so does reality as we know it.”
Thalamus(LGN) acts as the gatekeeper, allowing M-pathways to bypass for unconcious attentional capture, while P-pathway requires full conscious processing before meaning is resolved.
For example:
We can Imagine that this is like going for a trip, you arrive at the airport and now you need to
go thru the security inspection.
What ticket you are holding in your hand matters a lot.
If you have Business class - guess what- you propably have priority lane on
every stop, allowing you to bypass normal que and reach the gate much sooner.
But if you hold economy class, you will go thru every inspection waiting in a que.
But even if you have priority, if you are late arrival, it might just happen that everyone
else has already boarded the plane before you….
.. and sometimes, the flight might have already left without you completely.
ADHD
Multiple neurobiological studies on ADHD directly support the collapse-verify framework.
DelGiudice et al (2010) found significantly reduced contrast sensitivity in children with ADHD.
That would implicate M-pathway dysfunction and delayed collapse.
Hale et al (2014) demonstrated rightward-lateralized visual cortex activation and reduced DMN
suppression.
That would refere to a reliance on bottom-up input and failure of top-down verification.
Additionally, Misra & Gandhi (2023) reported elevated temporal variability in parietal-visual attention
networks with ADHD.
Reflecting instability in the proposed feedback-loop of collapse and verify.
These functional and connectivity disruptions align precisly with a model in which impaired magnocellular input weakens rapid meaning collapse,and deficient parvocellular feedback compromises coherent perception.
AUTISM
In autism, parallel timing misalignment between M-and P-pathways results in system overshooting and undershooting.
High detail-focused Performance on specific tasks, and yet underperformance when fast global integration of spatial and social meaning is required.
Simultaneous, unsequenced actions toward resolution lead to strong local abilities but difficulties with global, semantic or social contexts.
What it means in the context of visual logic, instead of clear sequential architecture(collapse-verify), there is simultaneous or mistimed processing,leading to perceptual and cognitive challenges.
Soulieres et al.(2009) found superior local processing (P), but global (M) deficits in autistic individuals
during imagery tasks.
Milne et al. (2002,vision research) Children with ASD showed reduced contrast sensitivity for low spatial frequencies.
Koldewyn et al. (2013,Brain) reported with fMRI that ASD participants had weaker MT/V5 (motion area)activation when viewing moving stimuli and Robertson et al. (2014,Neuron) showed atypical M-pathway development leading to hypersensitivity to flickering and flashing lights.
Bertone et al. (2005,neuropsychologia), Mottron et al.(2006),Frey et al.(2003) all showed enhanced P-pathway.
EEG/MEG findings from Boeschoten et al. (2007) discovered dealyed M-pathway responses (~100ms post stimulus) but faster P-pathway processing.
The evidence from autism research strongly supports the collapse-verify architecture.
M-pathway connectivity reduces global scene simulation (collapse), while enhanced P-pathway processing produces hyper-detailed but fragmented imagery (verify without scaffold).
These findings extend the model beyond typical perception, into neurodiverse cognitive architecture.
Autism does not appear to be just a "social" or "behavioural" difference in the light of this.
But more an alternative perceptual collapse-verify dynamic.
DYSLEXIA
Developmental dyslexia is consistently associated with M-pathway dysfunction, evidenced by reduced motor sensitivity, lowered constrast detection and impaired structural connectivity between (LGN) and (MT/V5) along with relative parvocellular compensation.
(DelGiudice et al.2020,Stein et al.1997,Muller-Axt et al2017) and recent case control studies 2025)
Interventions targeting magnocellular functioning have demonstrated significant and lasting improvements in both visual processing and reading ability.
What it means is that the recent evidence are showing the trainability of the M-pathway in dyslexia.
In context of Visual Locic:
Sys1 collapse is a modifiable, plastic mechanism rather than a fixed reflex.
It is a race, but evidence suggests that we can in some extent manipulate the rules.
Several studies have explored whether training the M-pathway improves motion processing and global perception in individuals with ASD, while results are mixed, some promising findings suggest that M-pathway interventions may help stabilize perception and reduce hypersensitivity.
Wang et al. (2021,scientific reports) Robertsson et al. (2016,current biology)
The early evidence does point towards that M-pathway training can help stabilize perception in ASD, specially for motion processing and sensory filtering.
However, more controlled and large-scale trials are needed.
CONDITIONS OF EXISTENCE
If we now turn our attention to the final piece of the puzzle, and what could explain the “timing paradox” still existing in modern theories of perception.
Like mentioned before, where and what, are composed from information thru the m-and p-pathways, and here is where it gets interesting.
To consciously exist, where and what are not enough.
Where, What and When - determines whether you share the same space with others. When = verified and validated / timestamps this experience into memory.
How does that happen.
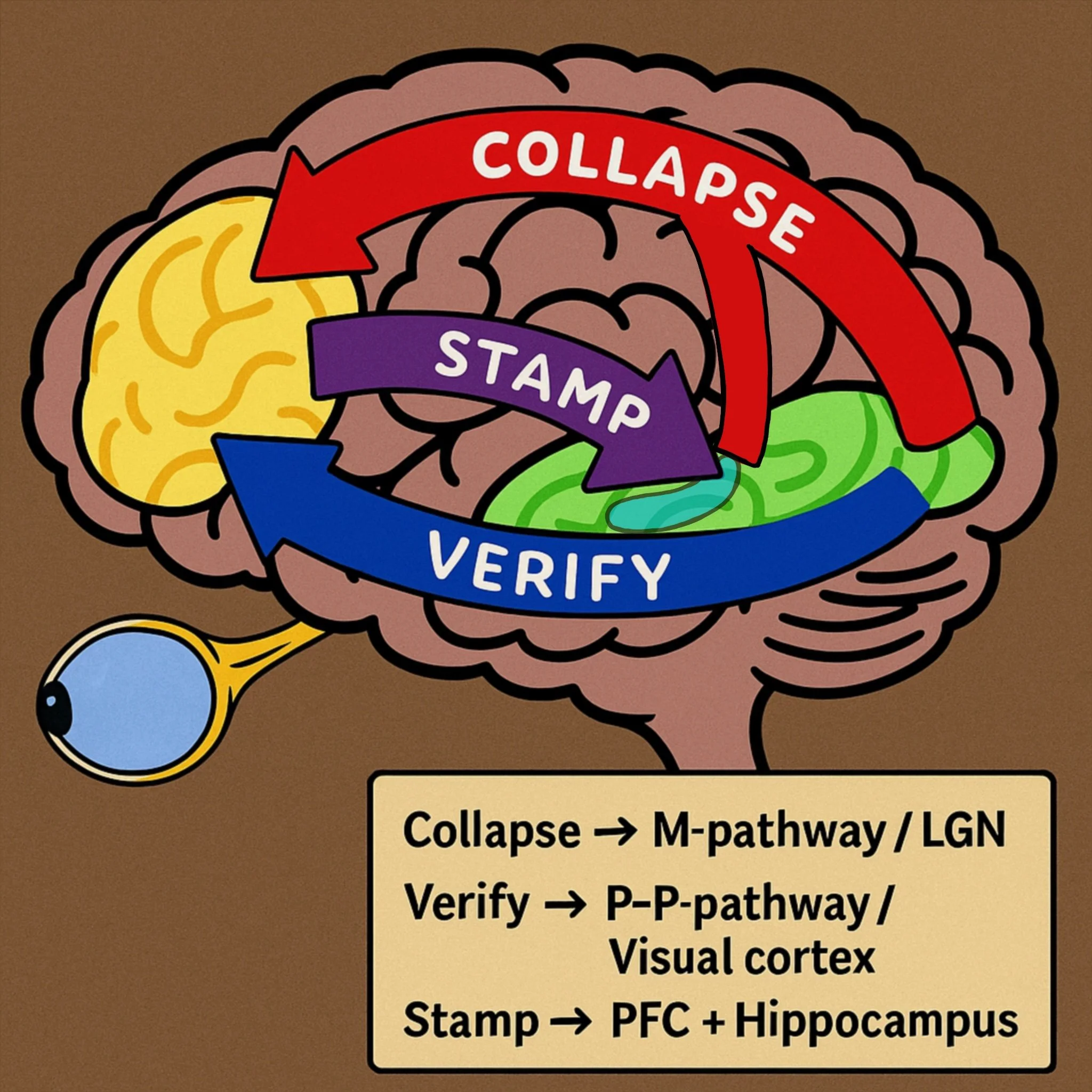
Once both (M/P) path delivered information to PFC, it will be validated, and then sent back thru ventral stream to hippocampus, to be encoded and archieved to STM (short term memory) and LTM (long term memory).
Existing evidence of sleep walking and sleep fmri, show that during such period, ventral stream is shut down. And furthermore, prior we went thru how in sleep phases P-path is supressed. It very much seems that, active p-path is required for functioning ventral stream, and this could indicate possibly why we do not have effective memory of our dreams.
For experience to be archieved as lived experience, ventral stream is required. But if then P activity is required for the activation, nothing really gets thru into LTM.
This explains some parts of why people who suffered brainstrokes, and lost the ability to "archieve” recent memories = They live in the past, while still showing the normal personality (recognises family, behaves “normal”, but with with slight confusion and disorientation.
“Did we eat already? what day it is?”
“What” you see does not match ”When” - M and P can recognize everything, but this verification without timestamp is critical part to hold us in “shared reality”.
This points out to the direction, that not all memory disorders have to be in primary areas malfunctioning, it could well be deficiency of p-path activation in returning the timestamp to archieves.
Two stream hypothesis is not new, such function was already described by David Milner and Melvyn A. Goodale in 1992. They organized array of anatomical, neuropsychological, electrophysiological and behavioural evidence for their model. They replaced the dorsal- where, with how - stream.
Norman J.(2002) proposed a similar dual-process model of vision. He predicted 8 main differences between the two systems that were consistent with other dual models as shown here:
M- and P- paths are seemingly not simply a data wire mechanic. But play far more extended role of what becomes lived reality itself.
CREATIVITY AS NATURAL PLAY INSIDE THE TIMING
Creativity has been “hot” area of discussion in behavioural psychology since George Land expanded his creativity test from Nasa to wider public range. Kahneman connected creativity with intuition and proposed the dual system architecture in cognitive science. Fast and slow.
In relation to Visual Logic, the biological structure shown here so far indicates that M/P control far more than just data transfer.
Earlier, we went thru research regarding Dyslexia and clinical evidence showing the plasticity of M-pathway = treatments targeted to stabilize M-path defencies . And other studies indicating that P-path can possibly be affected as well to create non-invasive supporting treatment protocols to stabilize hyperactivity and deficiencies more effectively. So if we accept the collapse - verify -stamp model, we can start looking once again to wider fields and connections this impacts.
Kounious & Beeman (2014) - the Aha! moment - found that sudden creative insights correlate with alpha-band suppression in visual cortex. That is linked to M-pathway processing. fMri revealed increased activity in right anterior superior temporal gyrus during insights that are fed by rapid M-path inputs.(sys1)
Jung et al. (2010) discovered that high-creativity individuals show greater P-path(sys2) integrity for detail-focused tasks such as realistic drawings. fMRI showed (V4) and LOC activation during detailed visual imagination, which indicates that creative persons could possible have “trained” their ability how and when they adapt to it.
Study by Ellamil et al. (2012) saw that early-stage sketching activates dorsal stream (sys1) for spatial layouts and when entering refinement ventral stream activates. fMRI showed MT / V4 shift during creative process, Implicating that it is a systematic function based on what is required.
Biologically - Development happens similar way, we have intact M-path developing way before we even are born. Huttenlocher (2009), Braddick et al (2016) pointed out that M-path is intact in the retina at week 20-28. fMRI images show that infants 30+ weeks exhibit dorsal stream activation (MT/V5) to moving stimuli. That is also why the baby turns towards voice. P- pathway develops way later, the cells exist but lack fuctional thrichromacy that develops 4-12 months after birth , and reach to adult level function closer to 5 years.
In a way, Vision does not begin with light extraction, but with motion experience.
You might wonder did we get sidetracked, and no, just keep reading. This will all make sense very soon. Developmental stages are quite fascinating and key features, even though underlooked in most cases and research. They will provide wider logical structure for my claim- collapse, verify, stamp, from the point that it is not just biological necessity ( because I said so), but a developmental logical outcome.
Let´s return to George Lands creativity test, it showed that 98% of kindergartners reach a level creative “genius”, 10 year old’s only 38% reached the same level. And by the age of 15 only 10% were able to reach it.
When the test was performed to 200 000 adults, 2% had that ability. Pointing out that we seem to be “learning” out of divergeant thinking. In the sense of Visual Logic, we do not “unlearn”, but rather grow out of it as P-pathway develops and systems begin to stabilize.
Peter Skillman created a task that was conducted by business school students against kindergartners. It is called the famous “Marshmallow challenge”. The task was a group challenge, where the goal was to build highest possible structure that can hold the marshmallow on top, with limited supplies that included spaghetti, tape, rope and the marshmallow.
Kindergarterners over performed, reaching over 50cm on average. Business school students on the other hand underperformed and managed to create a structure of 25cm in height.
So what happened?
Based on what is known from the process, children show to be far more braver with practical exploration and experimentation.
We could say - they were more eager on getting their “hands dirty” to aim for the highest possible structure.
As adults spent more time on designing hypotethical structure and how to plan and proceed in practice, they wasted precious time that they had on actually testing it.
This type of problem is common and known as “Analysis Paralysis”.
That means that person enters a loop in the thought process, which results in “over-thinking” of the task and problems. With each problem that is solved, new one emerges. In context of Visual Logic - Sys2 is the dominant force driving towards the resolution. Biologically, P-path is heavier on computation, which we referred to earlier with example of chess players burning calories.
Similar way, when learning happens in our traditional education, it requires much more P-path like processing. That is why you feel “drained” when reading and preparing for exams. We have long used the term: “playing is the work/education of children”
Or as Lev Vygotsky noted; “ Play is not a break from learning but it´s highest form”
This directly echoes in Land´s creativity test and the Marshmallow challenge. Our whole reform of schooling evolves around this, pedacogically - from preliminary to high schools. The younger we are, more intuitive tasks are. But somewhere on the line, we switch from intuitive tasks, to spesific and literal. And we are unable to maintain both as cohesive and joint structure.
We seem to be following or favouring either one, and lack the ability to maintain both. We will return to this at the end of this article with my proposals based on what Visual logic can offer in this context.
Mihaly Csikszentmihaly is known for introduction of the “flow state”, which refers to uncounscious existance, outside of time and presence in physical environement.
For example
While driving a car, you have experienced a moment of falling into a state of deep thoughts about something. And suddenly “collapsing” into reality and realising you have traveled a long distance. “ Have I a past red lights? How am I almost at home?”
Or while doing hobbies or a task at work, or perhaps playing your favourite video game - several hours might have passed and you have not realised it.
Most of these are things that are familiar or interesting to you, or might not even have task that requires P-pathway or triggers M-pathway more. ( like flickering and motion in video games) - You enter a state of “automation” that allows you to keep doing the task but to also enter a state of “ mental imagery”.
Much like artform and method known as “automatic drawing.” Or while reading a good book. Which becomes explicitly hard process for aphantasiacs as my interview with aphantasiac tattoo artist shows.
Computationally, this is cost-effective and connects the ideas of Karl Fristons free energy- principle.
Sys1 state of unconscious actions allow us to have ability to be multi-tasking if the task is memorized, and can be done without the need to constantly be verified, as pattern based operation.
While the “flow state” has not been involved with researches strictly focusing on fMRI of magnocellular and parvocellular activity - It should be, and here is why:
Flow´s “automaticy” matches M-path dominance. It involves effortless focus, time distortion and loss of self-counsciousness, all hallmarks of Sys1 (m-path) takeover. fMRI could test if flow supresses P-path verification or delays it, with reduced V4/LOC activity.
Kounious & Beeman (2014) “Aha” moments show dorsal stream (M-path) bursts before the ventral refinement and Dietrich (2004) suggests that flow correlates with PFC downregulation, that would mean in plain terms that as “stamp” -mechanism fails, it leaves pure collapse.
This would indicate strongly, that as full-fillment of verification loop remains open, so does the options. Nothing is committed to in counscious state. This could very well explain why creative thinkers, see multiple solutions and ideas when inside the described flow state. Beyond the studies, I know this state well. In my own life it takes a form my wife jokingly calls “Mikkolandia” - a kind of screensaver mode. From the inside, it feels like slipping into automatic motion, where ideas and connections appear without any deliberate effort. Many of the links that became Visual Logic emerged in this state. I did not build a hypothesis and then chase evidence. But more so, evidence appeared within this flow until the framework revealed. This does mirror the very principle I am describing: we don´t see what is, we see what survives from the collapse.
As the theoretical part of my claim´s are now presented in context of the original “what does it take to see at all” - we can shift in to my own experiments and real-world practical evidence. You didn´t think after all this study and research I could resist getting my own hands “dirty”.
After all, even if half of what I propose here holds and in future becomes to be shown true, then this is far more functional and foundational, in a sense of what it can be practically transformed and applied into.
And if something claims to be so profound in a deep, complex structure. Still, it should reveal itself already in the most simple observable forms.
DRAWING TASK - The hunt of CVS

This drawing task is the simplest real-world demonstration of everything argued so far. If collapse - verify - stamp is real, it should reveal itself here.
Originally, I designed it only to show that visual art is not about how one holds a pen, nor about experience or “talent”. My own growth as an artist came not from mastering techniques, but from learning to trust my brain. Once I realized that vision itself had been training me since infancy, I understood that anyone could draw and reconstruct - even without prior training.
That insight expanded across media: from drawing to painting, from dyeing materials and printing shirts to digital art. Then into 3D sculpting, rendering, and finally testing developmental AI tools.
Each step required no reinvention of methods, only recognition that every medium respects the same fundamental phenomenon: light interacting with material within human sensory thresholds. The medium changes the limits, but the logic remains constant.
What began as a simple task soon revealed itself as something much more. A possible proof of principle.
Let´s take a look at the structure of it.
The initial design was based on what the task required:
- Realistic result ( impossible goal in the minds of non-artists)
- Result in matter of minutes (seemingly impossible idea even for artists)
- No clear instructions or guidance.
- Intuitivity prioritized
- Follows the natural reconstruction of image in humans
Then the subject was chosen, it needed to be something very familiar from our daily lives. Something that we see several times a day - eye.
Either from social situations, mirror, media platforms - we observe eyes constantly.
The design then was constructed based on Yuan & Brown´s fMRI studies of drawing, which allowed me to exclude techniques that risked activating the P-path.
The process of the task contains seven steps, each demanding only observation, visual comparison and replication.
Moving from ambiguity to clarity and detailed refinement.
Parvocellular interference at process was then deliberately minimized = No “Analysis Paralysis”
At the beginning, the task was done as part of my private workshops with charcoal drawing. Then I included it as part of my lectures and professional seminar for Finnish tattoo artist association, and finally in two public events, first one being the huge Kädentaidon messut, at the convention center (Pirkkahalli) in Tampere and Tampere Tattoo and art festival.
The feedback from participants of all ages, that included non-artists, hobbyists and professionals, was remarkably similar when describing the task (across over 180 participants)
Most described loosing track of time and their attention to the surrounding environment. Even in a noisy convention hall where thousands of visitors were roaming, many described it as refreshing break, a recharging moment.
It was when I began hearing the phrase ; - “Everything just seemed to click! and the task felt very logical”, more often, that I realized this might no longer be just another workshop trick. From then on I decided to begin documenting more specifically the performance and experiences.
The task itself does not have set time limit, but generally people are finishing it in 10-15 minutes, and some even as fast as 8 minutes. For now, I have not included children under 13 in the documentation, since the developmental stages can create mixed results. But they are always welcomed and encouraged to join in. As a matter of fact, everyone is always invited in the public events to participate, and the ones who wish to submit their experience are the only documented cases.
Here are some results from the non - artists.

Picture A (T8) is from 71 year old person that has not been drawing since childhood.

Picture B (T1) is from 40 year old who has not been drawing more than casual stick figures since childhood.
Here are two drawings from hobbyists:

Picture C (T6) is from 40 year old hobbyist:

Picture D (T7) is from 46 year old hobbyist
And from the earlier mentioned case study:

Picture E (A1) is from aphantasiac tattoo artist, one of the fastest performances under 8 minutes.
And final example from my daughter that was 11 years old:

While full disclosure of the task itself is not yet revealed, as it is ongoing with goal to reach 200 documented cases within the next 12 - 18 months, the early results are showing some promise.
Non-artists are reporting experiencing the click or Aha- moment with consistency, and what is so far the most interesting part, is that majority of them are pointing the moment on same specific phase of the task.
Artists on the other hand show more variety, often experiencing that moment far sooner compared to non-artists, and many of them reported experiencing that more than once in different phases of the task.
This possibly indicates to the difference of non-trained and trained pathways. And does align with the earlier mentioned studie of Jung et al. (2010), that high creativity persons might have learned to switch between systems based on what is needed.
Future research with fMRI is required, once enough cases are documented before further conclusions can be made.
WHY THIS MATTERS
While my research with this focuses on tracking my proposal, that visual reality, or even the idea of reality is cellular-driven mechanic CVS. Still, already as simple task structure, it can be applied into what already is known and practised.
If we start from clinical and therapeutical appliances, it could be already used as non-invasive supportive treatment for M-path deficiencies. It lacks the weaknesses that video games provide, in a way that they trigger P-path as well, introducing disruptions to the sequence.
Not proposing to replace them, but to include amongst them. The task itself, can be replicated with several different subjects and mediums. The task itself, can be done with pages and tools on paper, or - it also already exists as online version, where the phases are presented with flicker, and could be done with real tools, or even transformed to digital art. Providing more wide spread practical possibilities.
So far the connection with different conditions, how they are related and already revealed with deficiencies/hyperactivity in the dynamics inside the pathways, could now be turned in possible non-invasive diagnostic protocols as well. This type of task structures could be introduced even with VR/XR, to test with multiple different simulations, including specifically targeted adjustments of stimuli in rapid speed, with multiple scenarios far more efficiently that current practices can provide.
For elderly, drawing is creative and there are not many activities existing necessarily for older people who have lost their ability to live by themself. Or who suffer from different type of memory losses.
Not to provide cure, but to support and prolong the quality of life and support to stabilize pathways. These pathway defencies are known to exist in parkinson decease and other forms of dementia.
The subjects of the drawing can be changed to include objects and scenes from different decades, adding sentimental value, familiarity and sparking memory patterns.
For creative fields, it can produce targeted and specific task structures that are based on known biology. Something that has not really existed before. The tasks are rather generalized and lack co-ordination and coherency to what is tested, or they implement too wide variety to remain consistent and true when applied.
During these public events, amongst the participants there have been school teachers as well. And so far they have been interested what the task itself can provide for art classes already. Most of the kids love to do it.
By changing the subjects, mediums and tools, it already is easy and quick creative task that renders into something with realistic appearance. And since it does not involve any prior technical skills or long practice hours to understand theory or instructions, it fits perfectly into art classes of the basic education. Thus providing actual real practical tools for teachers.
And let´s be honest: education is in crisis and needs this kind of structure. The world and technologies move faster, information spreads unfiltered and too often educational practices are adopted based on funding speed rather than evidence. When that happens, methods become facts by support, not by proof.
Teachers are then expected to implement them without coherent tools, and when results decline, they carry the blame. This cycle is neither sustainable nor fair.
Visual Logic offers a different path. It is an addition, not a replacement.
It provides a set of tasks that are scientifically grounded, cost-efficient and creative. Yet simple enough to deploy immediately with existing art classes.
Teachers gain tool that works with what they already do, while students gain a new way of seeing and creating that ties directly to the very technologies shaping their future. In this way, practicality stays primary, and evidence remains the foundation.
TRAINING THE OBSERVER
If you are worried that theory does not belong in art class, I agree.
Art class should never become a lecture hall - it should remain a play and discovery. But the play can be structured to prepare perception for later science.
Art classes work best as supportive tools, inspiring the mind through practical, intuitive, creative mechanics. It´s not about teaching a six-year-old the physics of light and matter. It´s about giving them delibarate tasks where they experience the difference - the answers can and will come later. And when they do, the children will already have the perceptual ground to understand.
For example:
When my daughter was nine years old, she asked why mixing colors too much made them “disappear”. I asked her; what color is a red ball under green light?
She hesitated :- red, no its green , no red again?
And I said, it´s the same as when you mix too much. Every color works that way.
Color does not belong to the object. They only reflect what light leaves behind. Much like you eat only part of your meal and leave the rest.
Of course she could not grasp it in words, but when we placed different colored objects under cycling LED lights, as my example here shows, she saw it directly: matter changes color depending on what is offered.
Few years after in physics class, when the lesson was about photons and wavelenghts, she had no trouble.
She already “knew” it, because she remembered the magic, and when science arrived, it already had a place to land.
Let´s take a look what training the observer can be like. It is not far from what we are doing already from kindergarten, but what we lack is the purpose and coherent timing. We introduce play with exploring things in our environment and with painting.
CONDITIONS OF SEEING
Age group: Early art/science activities ( 5 - 10 )
The first stage can be applied from:
Light, optics and material interactions with visual simulations & perception.
These would include hands-on experiments with: RGB lights, shadows and fingerpaints etc. and different drawing tasks.
For example:
Creating colored shadows from different shapes by cutting silhouettes from cardboard and placing them in front of three flashlights that are Red, Green and Blue as shown in the example video. By changing the angle of lights or switching their places, the shadows will be colored differently.
Adding pieces of mirrors or painting letters for example, you can create light installations and illusions.
Goal: Teach kids to understand without explaining, that mixing colors with light is different than mixing colors with matter. They only need to understand the difference of the mechanics.
Once they can distinguish between them, they are ready to explore the tricks and limits of perception itself.
CONDITIONS OF APPEARANCE
Age group: Middle grades ( 10 -15 )
Second stage can be applied from:
Sensory thresholds & perceptual systems, based on filters, optical illusions and digital drawing including “game-skins for 3D” - rendering.
Exploring illusions by creating perspective distortions that appear correct when observed from spesific angle. Creating drawing/painting with the combination of red and blue color- look at the drawing thru colored filter and you see only different parts. Learning to mix the same color from multiple different pairings. And at ages 14 - 15 digital drawings of maps that will render in 3D as “real”.
For example:
Shader logic in 3D rendering, why the surfaces appear real, is just visual code. Those maps can be made by drawing, without ever touching a 3D app. They are simple and easily done. Kids will learn the most valuable part of 3D technology, the rendering of an image. With just few maps, you can create illusions of objects when the maps are placed in the correct slots as shown in pictures below.
Goal: Showing students that perception is relative and adaptive - appearances change depending on conditions. They will understand how the filters they use with social media apps are working with the same principle. Combine this with the simplicity of 3D maps, and they will understand how technology adapts these principles instead of inventing them. They can then begin to question, how perception builds not just images, but reality itself.
CONDITIONS OF EXISTENCE
Age group: Older students & interdisciplinary programs.
Third stage can be applied from:
Neurology, cognition, creativity and system-level understanding.
Drawing links between art, science and technology.
Connecting shader logics of 3D renderings to Ai systems. Philosophy of perception and creativity as a trainable skill.
For example:
Contrast, saturation and perspective are not physical properties, but they are psychological properties. Thresholds inside our biological sensory dynamics = Observer biased perception that is not just about images, but about constructing reality itself.
Drawing task could be used not just as a task, but with how it is structured.
Or that wavelengths (colors) in physics, are energy transmission related. The bases of spectroscopy, and the same foundation is the core of 3D rendering engines.
Students could experiment on distorting reality by building VR filters themselves.
Goal: Showing that the development of systems and tech, rises from the same foundation and only differs based on where it is applied to.
Visual Logic doesn´t replace art class. It restores art´s original role: training the observer. Giving perception a structure, long before theory arrives. When students later meet physics, psychology or even AI, those ideas already have a place to land.
WHY WE SHOULD DO THIS
Children now grow up using technology earlier than any prior generation. This creates a natural gap: even adults often don´t fully understand the tools their children are using.
To close that gap, we must return to the source where all disciplines connect:
art.
The best part? it´s cost-efficient. Nothing needs to be replaced or restructured. A teacher only needs to know how to open a model in Blender(free software), drop maps into right slots and turn rendering on. Nothing else.
I already have a library of 3D assets and maps, and the web is full of free models.
I´ve built a simple online course that explains these maps - but honestly, most schools already have 15-year-old who has made Counter-strike skins and could teach their own teacher how it works.
Colored shadows can be created with nothing more than a clear tape and markers on a flashlight. That´s the beauty of art: it builds from what already exists, and transforms it into discovery.
Within 12 months, we could build an online library of classroom-ready assets and examples. Teachers could browse tasks, download instructions, and apply them immediately. Each task would also give teachers a cross-disciplinary update, showing how perception, art, and modern technology are linked.
WHY AI FAILS WITH VISION: The Crab experiment
In early 2025, I applied to participate testing a new 3D Ai tool that was in development. After the interviews I was accepted to the closed testing phase. It soon revealed that while these systems are improving, the fundamental problem remains.
3D Ai must resolve fundamentally different challenges, than 2D Ai does with images or video animations. They are initially just RGB “pixel-lighting”. Meaning, that images and frames are just RGB based “clean data” . Flat illusions of depth, much like paintings or drawings on a surface.
Once real depth is introduced, it brings a lot more to the table. 3D is not just color and light . It is orientation, local vs. global symmetry. Spatial awareness becomes priority. In short: it begins to behave like reality itself.
SPATIAL AWARENESS IN NUTSHELL :
In 3D there is no “one space” , in a way, for each object to be part of it they need to carry their own “local space” .
Imagine each object surrounded by an orbit of satellites, that project images on the surface as shown below.

This is Tangent space
When you apply displacement or normal maps to object, you are not sculpting real geometry. You are feeding visual code to the shader. Instructions for rendering small textures and details that appear to be pointing outward.
You could say “height” , but it is not that easy. What count as “up” or “height” is different in every local space.
World space does not have orientation of it´s own, it is just axels. ( x, y, z) Orientation comes when objects enter that space and refers to how they are related to those axels.
Shader takes orientations and combines them with light directions, encodes the visual image to create an illusion of real looking fine textures. If every bump would be actual geometry, the polycount would explode into millions = making real-time rendering impossible.
In common words, your software, game engine or even you computer would crash.
This problem was solved by using visual codes, images as maps that are projected on the surface, like shown in the image below. On the left is the actual structure, and then how it looks like with maps. Pretty impressive solution and brilliant shortcut.

But as we are about to see with the crab, when AI “tries to see” through this system, the shortcut breaks.
PREDICTION VS. RESOLUTION
Common problem with 3D AI tools so far has been the the same as with 2D. Hallucinations.
For example:
Given a reference image and a prompt ( a description what you need and want) the system aims for “close enough”.
It doesn´t weight outcomes and decide, it settles.
That is why you see high-quality geometry paired with misplaced eyes, extra fingers or even distorted proportions like limbs being too long compared to another etc.
In the system I tested, the geometry itself was impressive, but the moment I applied textures, that “close enough” failure became obvious. Even with multi-view cameras, the AI could not prioritize what mattered: RGB alignment with geometry. Key features like eyes stayed coherent, but everything else drifted.
To test this further , I proposed a multi-view batching feature, letting me provide extra images to anchor the projection. This worked, “close enough” transformed into good enough.
As the comparison below shows, when the actual resolution is provided, “minimizing error” becomes efficient.
Without multiview anchoring
With multiview anchoring
However, this does not fix the problem. It requires more features always to the system, to batch up a flaw in the core:
The AI is not resolving; we are.
This is where the gap becomes fundamentally clear: prediction without commitment is not vision.
Humans resolve by collapsing ambiguity into meaning - AI only accumulates and settles. If Collapse - Verify - Stamp is the biological act of seeing, then any system that claims to see, must have its own mechanics for collapse, not just prediction. This became the architecture of experiment behind Biovision.
CVS MODEL - “BIOVISION” EXPERIMENT
To test the Collapse-Verify-Stamp in action, and to see whether such a mechanic could function as an AI´s core for vision, I built a protype in PyTorch and trained it in Jupyter Notebook.
The first stage reproduced M- and P-path dynamics with threshold gating. Once those interactions proved viable, I moved on by adding memory loops to system, creating the base structure of CVS.
Training revealed fascinating outcomes in how these pathways negotiate, and not only that, but that their behaviour could be directly influenced thru the core architecture itself.
To establish a baseline, I trained standard “vanilla” CNN for comparison. The difference was clear. Biovision showed a far more active learning curve from the start, while Vanilla CNN remained stable and constant.
This suggested that the developmental stages in biology, could possibly be simulated in Biovision. Adaptivity was introduced with logging mechanisms.
In the second stage, the training was scaled to Modelnet40 voxelized 3D classification, with 30% of samples degraded using Gaussian blur and random erasing - to test Biovisions performance under ambigious and noisy conditions. The early runs started to show what the CVS model predicts: instead of “guessing”, Biovision seemed to be more actively “resolving”.
OVERRIDE DYNAMICS AND HAPPY LITTLE “ACCIDENTS”
Third stage focused on how verification behavior shifts during longer training runs (80 epochs), and how much regret memory influences whether P overrides M.
When P overruled M and turned out to be wrong, that case was stored and weighted against future decisions. In other words, the model was no longer just resolving in the moment, it was learning from its own failed judgements.
Based on the future errors, it was either rewarded or punished thru dopamine-like confidence adjustments. While tweaking this mechanism in the code, a mistake happened and the original Veto-threshold was disengaged. What I now call, borrowing the words of Bob Ross; “happy little accident”, revealed something extraordinary.
P-path stopped overriding M proposals on every step.
This “accident” provided evidence that external threshold was not needed anymore . With CVS principle dynamics, the system seemed to “naturally” mimic what the framework proposes.
Biovision wasn`t planned, and it is still not polished. But came the way Bob Ross said all good things do: thru “happy little accidents”.
That`s the difference between patching old models and creating something new. It didn´t just reduce error - it changed learning behavior.
Can I show that?
I know that since this section started, you have been waiting to see how it performed with actual data. While I could extend this phase and go thru Biovisions agreement rates and development in charts, I will save that later.
What you actually want to know is: How would Biovision perform against Vanilla in the same task with the same data? Right?
So I staged the match.
BATTLE ROYALE - CLASH OF VISIONS
What happens when you drop a Biovision and a Vanilla CNN into the same ring, same data, same task?
Who walks out?
No more theory, no more philosophy, just two models and one noisy dataset.
On one side: Vanilla CNN, stable, cautious, always the good student.
On the other: Biovision, noisy, impulsive, sometimes wrong, but always moving.
I let them clash for 80 epochs.
And the results? Well, I´ll let the charts do most of the talking.
Because in the end, vision isn´t about who guesses best. It´s about who commits.

Here are the average results from the full run.
It shows that Biovision is able to compete with the standard model exceptionally well. Clean and Noisy accuracies are measuring how well the model is training, and Test Clean/Noisy accuracy how well it performed.
Train and Test loss are not directly comparable, but allows us to evaluate stability, memorizing patterns, and generalization thru the run.
As we investigate what happened inside the run, it will reveal that the simple overall average is not telling us the whole story.
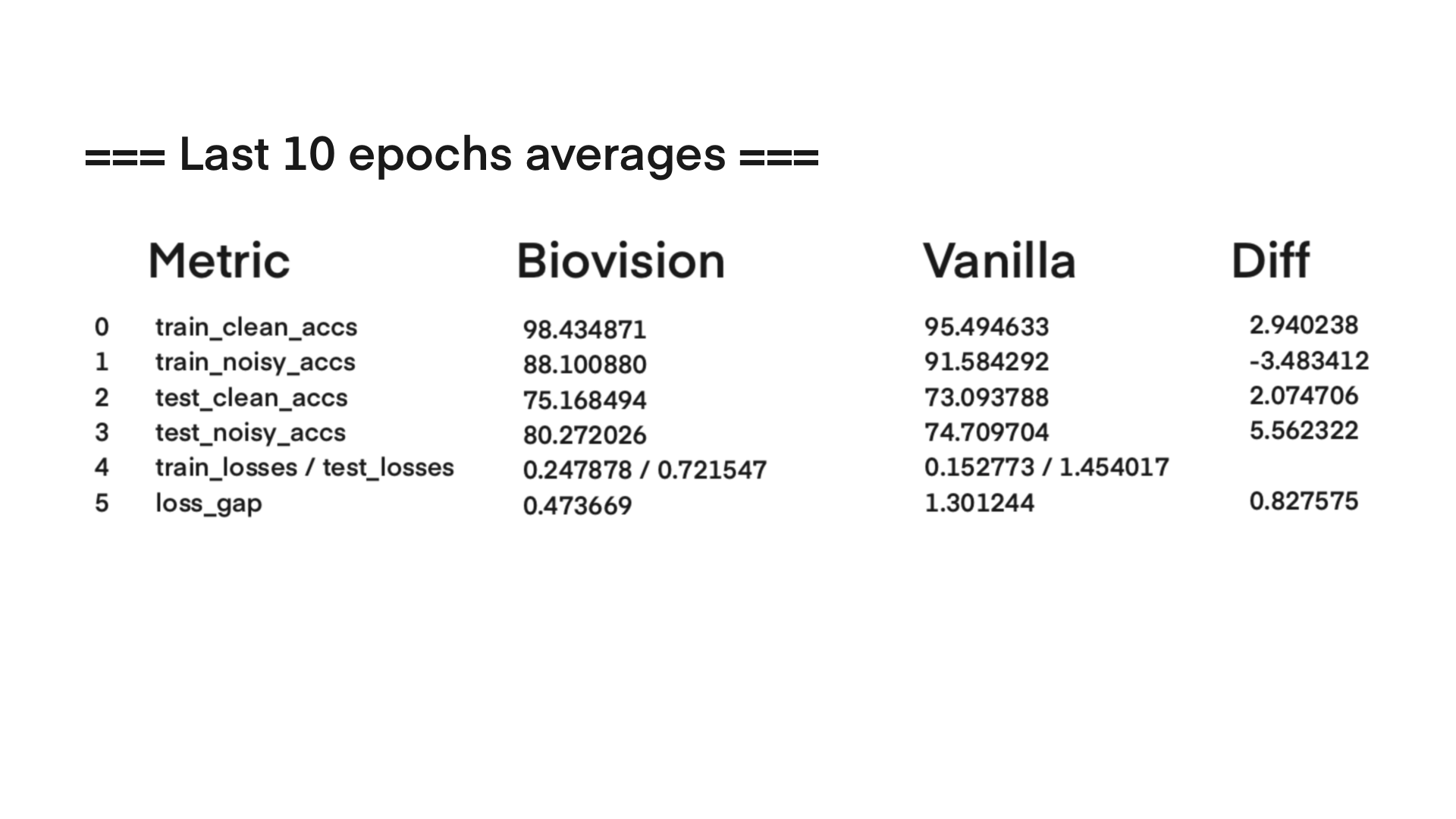
Here are the average results from the last 10 epochs and we can see that Biovision is not just holding strong, but taking over.
In Clean training accuracy, Biovision is higher, while Noisy remains lower.
However, if we look at the actual Test accuracies:
Vanilla is loosing in both categories and in noisy, it seems to be a full knockout blow.
Train and Test losses show that the gap is much smaller with Biovision (0.47), than it is with Vanilla (1.30).
This demonstrates that Biovision is less overfitting and more stable under evaluation, and I have the charts across epochs supporting this.
ROUND 1.
Training accuracy:

Clean: Biovision climbs early on and quickly to >95% and stays high. Vanilla lags behind, until epoch 40 beginning to catch up.

Noisy: Vanilla eventually overtakes Biovision, but as we already saw from the final ten averages - it begins to overfit since the test performance collapses.
ROUND 2.
Test accuracy:

Clean: Biovision fluctuates but remains competitive and shows long-term resilience. Vanilla starts slightly stronger but then collapses again after epoch 40 and cannot maintain early advantage.
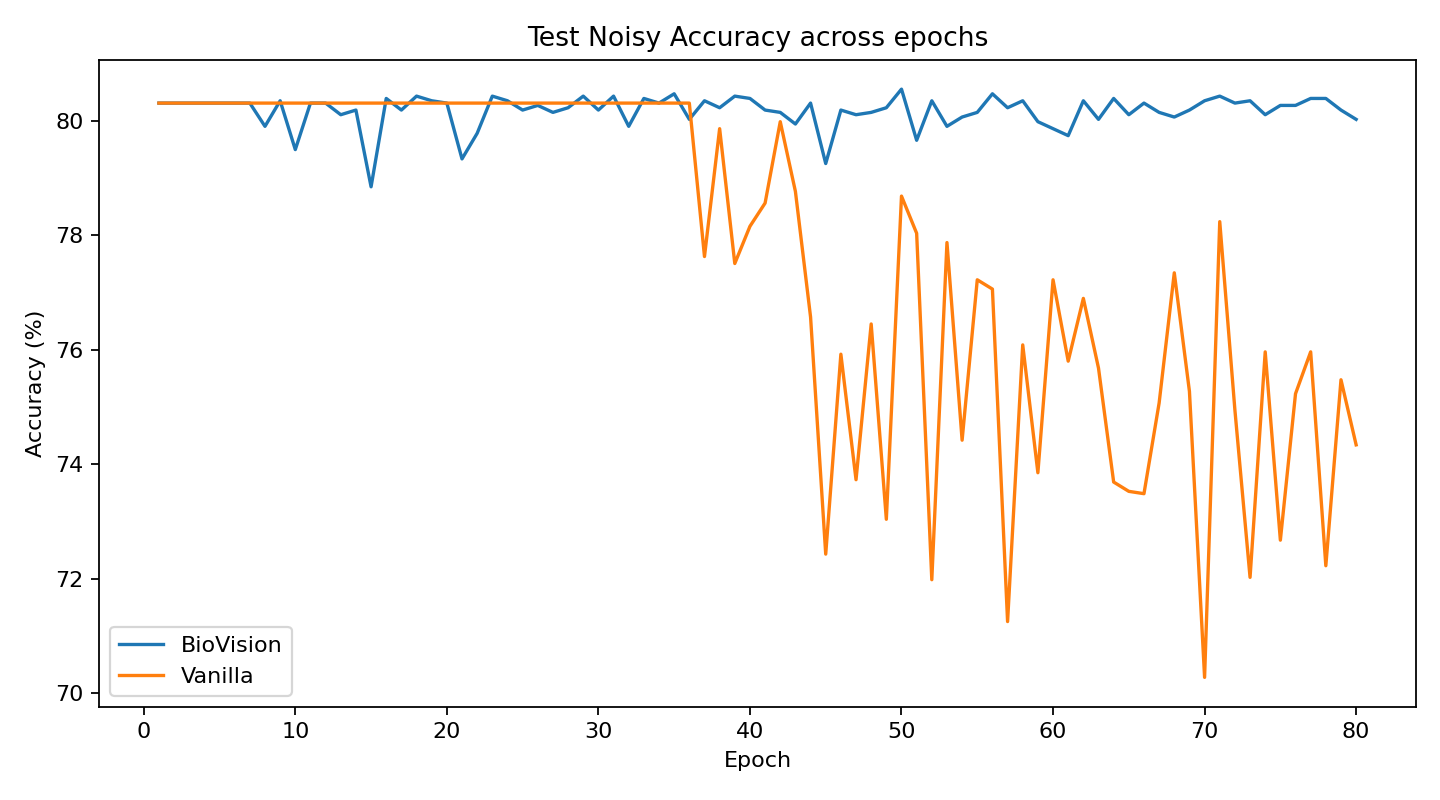
Noisy: Biovision stays rock solid around 79-80.4% the whole run. Vanilla´s collapse after epoch 40 demonstrates clearly, that Biovision has robust noise tolerance and stability.
ROUND 3.
Loss:
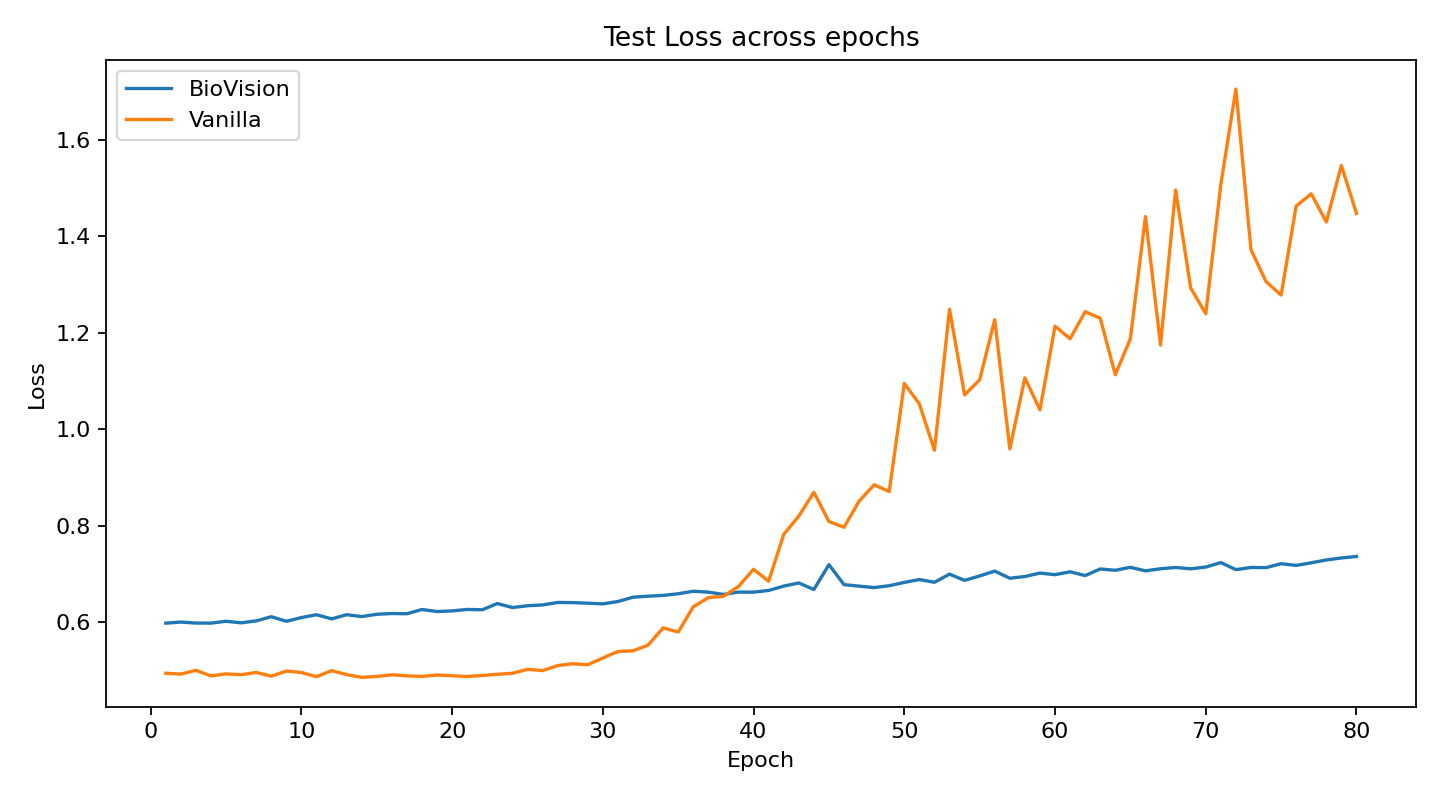
Test : Biovision has slow, steady and controlled rise. Vanilla low at first but after epoch 40, explodes exceeding 1.6 . Indicating that Vanilla drifts into instability and overconfidence.

Train: Training loss decreases more rapidly for Biovision early on, but Vanilla eventually overtakes, reaching much lower final training loss.
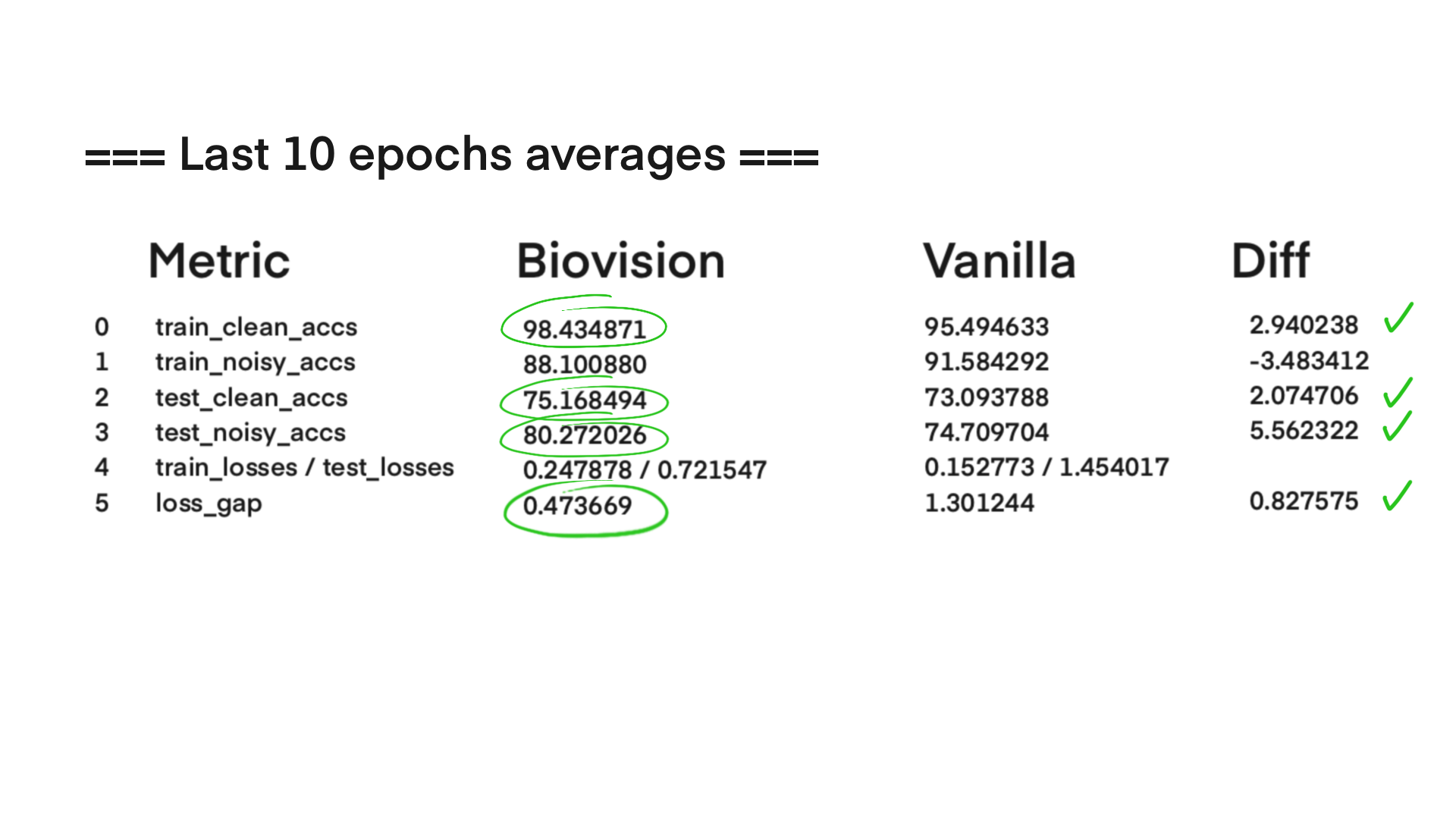
Judges scorecard: Biovision shows long-term resilience in the “championship rounds”
The head-to-head battle shows that Biovision does not just match a standard CNN, it behaves exactly as the Collapse-Verify-Stamp model predicts.
Biovision accepts higher training loss, resists noisy overfitting, and stabilizes test performance where Vanilla collapses. What first might look like a weakness (slower training gains and lower noisy accuracy in-sample), becomes greatest strength in generalization, robustness, and loss stability.
Providing the first concrete demonstration that perception-inspired timing dynamics can be encoded into machine learning.
CAN THIS BE A LUCKY MISTAKE ?
The answer lies in repetition. I ran multiple comparison runs, shifted timing, altered the thresholds - and the same negotiation pattern appears. This is not random, but structural.
Nowhere in the code are the pathways given fixed roles, or specified which pathway should focus on clean inputs or which one should resolve noisy cases.
With the timing dynamic of CVS, it was still a surprise for me. The system naturally seems to choose what to focus on. That is not luck. That is the first primitive step for meaning-based act towards resolution.
And this can be shown with charts again and again, because repetition is the antidote to luck.
Across repeated trainings on the identical dataset, Biovision struggles in the same epochs that are the hardest. But when I adjust the timing (and not just in one part), the patterns change in predictable ways.
CVS proposes that perception is a rigged race, where collapses happen fast, and verification comes later. Based on what is chosen, will be stamped as the final result. What matters is not only where but also when.
RIGGED RACE WHERE TIMING MATTERS
The clearest evidence comes from the run C14.
Here the P - pathway (Verification) was deliberately withheld until epoch 65. Before that point, collapses were unchecked, as shown in the images with green vertical line. At epoch 65 verification was allowed to enter and immediately stability emerged. This performance clearly demonstrates this instability.
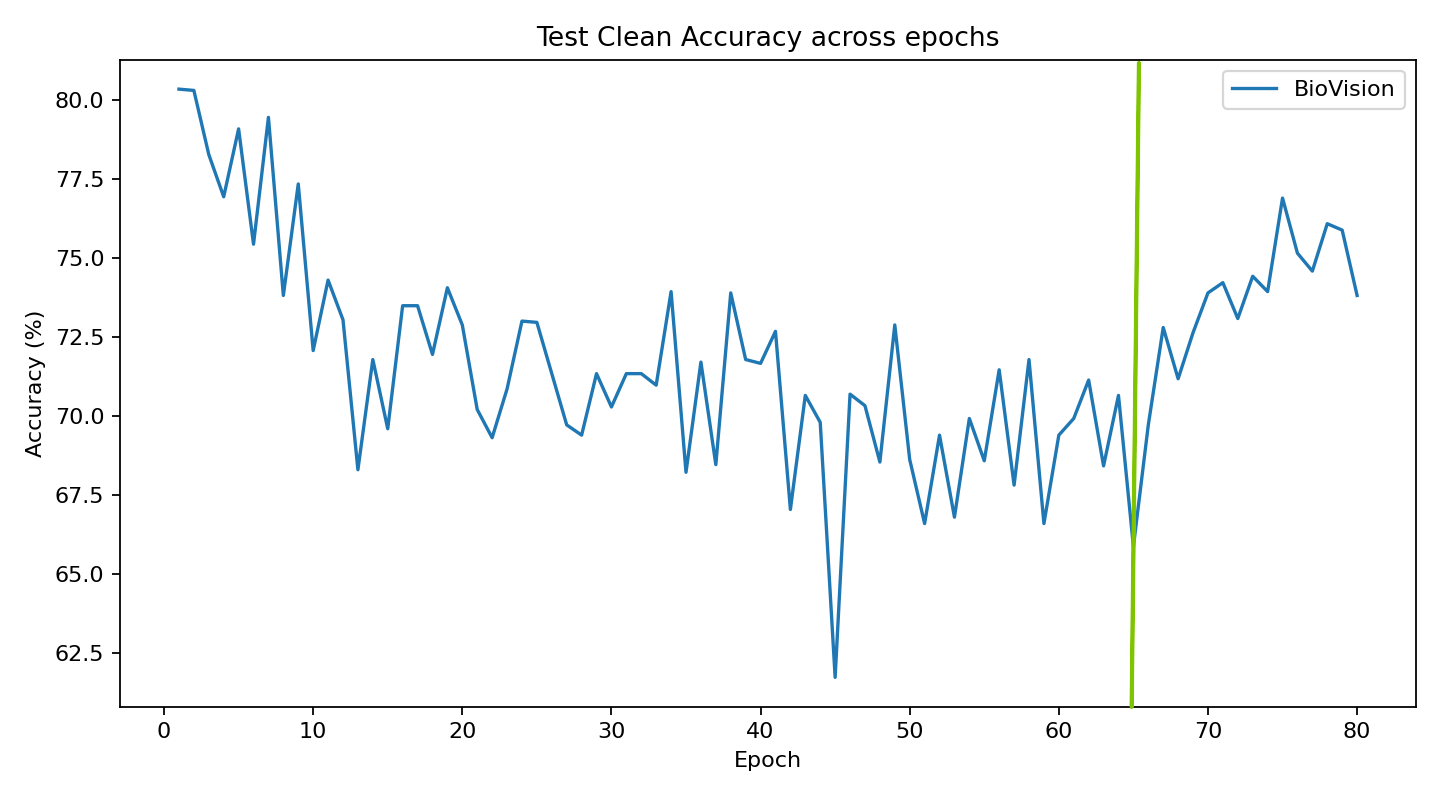
Prior to epoch 65 the test accuracy on clean oscillates and plummets, until post epoch 65 resurrection happens.
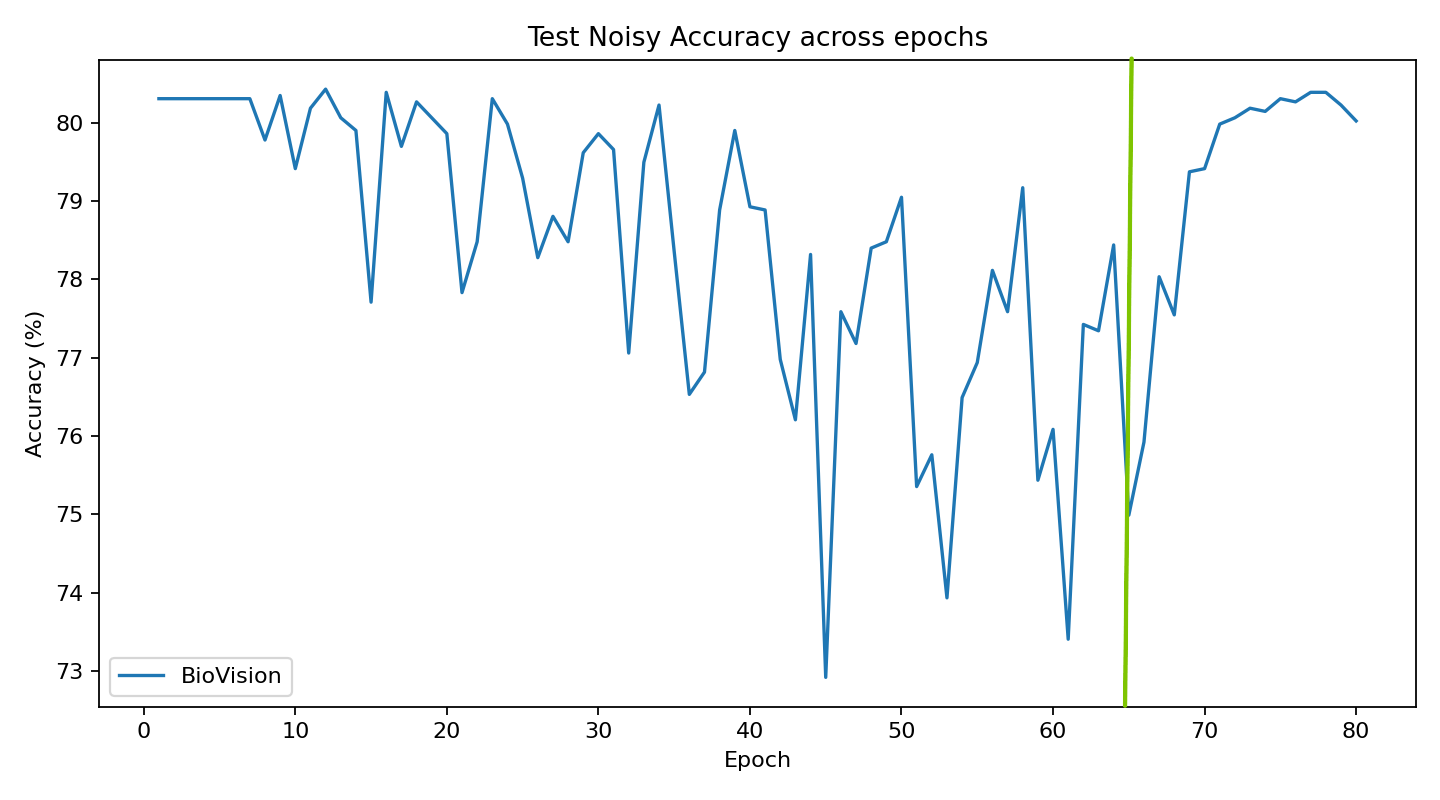
Similar trend can be seen here. Without Verification, Biovision swirls in to chaos until P-pathway emerges.
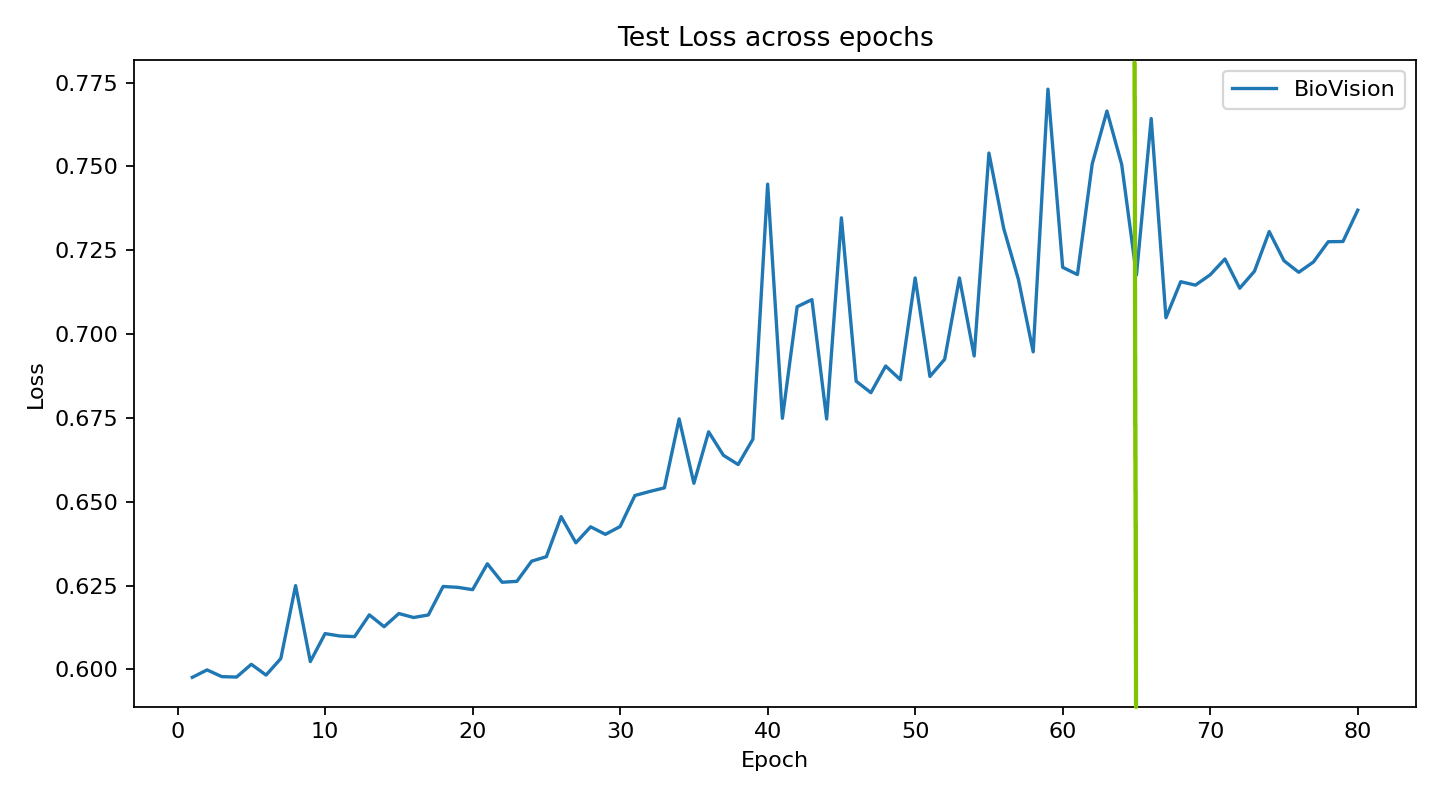
Test loss shows clear markers for overfitting behaviour prior to epoch 65, that begins to stabilize after Verification kicks in.
This is not random noise. With verification the system stabilized. The performance shift was not due to dataset variance or initialization, but directly to the negotiation between pathways and the timing of P’s participation.
C14 demonstrates undeniably, that verification matters for the outcome. The fingerprint of CVS: a dual-system dynamic where timing determines what is stamped.
As we move forward, it will become clear, that the stability of the system is depending on where + when = what
HOW DOES IT NEGOTIATE - Internal Observer
P-pathway (verification) is supported with two different memories. Episodic memory logs repetitive patterns, mimicking STM (short term memory).
Regret memory is built as primitive LTM (long term memory), that records cases where P-pathway used right to Veto (override) M-pathway, and was consistently wrong in doing so.
P-pathways confidence is then weighted against prior decisions, and either be rewarded (more influence) or “punished” (restricted).
In other words, It has an internal model to compare on with future decision making.
Changing these dynamics, has direct effect on the performance.
EXAMPLE: CLAMPING P’S AUTHORITY.
One adjustable factor is the confidence clamp.
Clamp sets the maximum influence P can exert when it disagrees with M.
This comparison is made between the original C3 and the modified C6
C3 (clamp=0.85) P has higher possible authority, but requires stronger confidence to override M.
C6 (clamp=0.51) P has lower authority, but can enter the decision process earlier and more often on borderline cases.

C3 - (0.85) Accuracy dips early on below 70%. With the higher clamp, P delays its participation until it is very confident, leaving M to dominate (and sometimes mislead) the early phase.
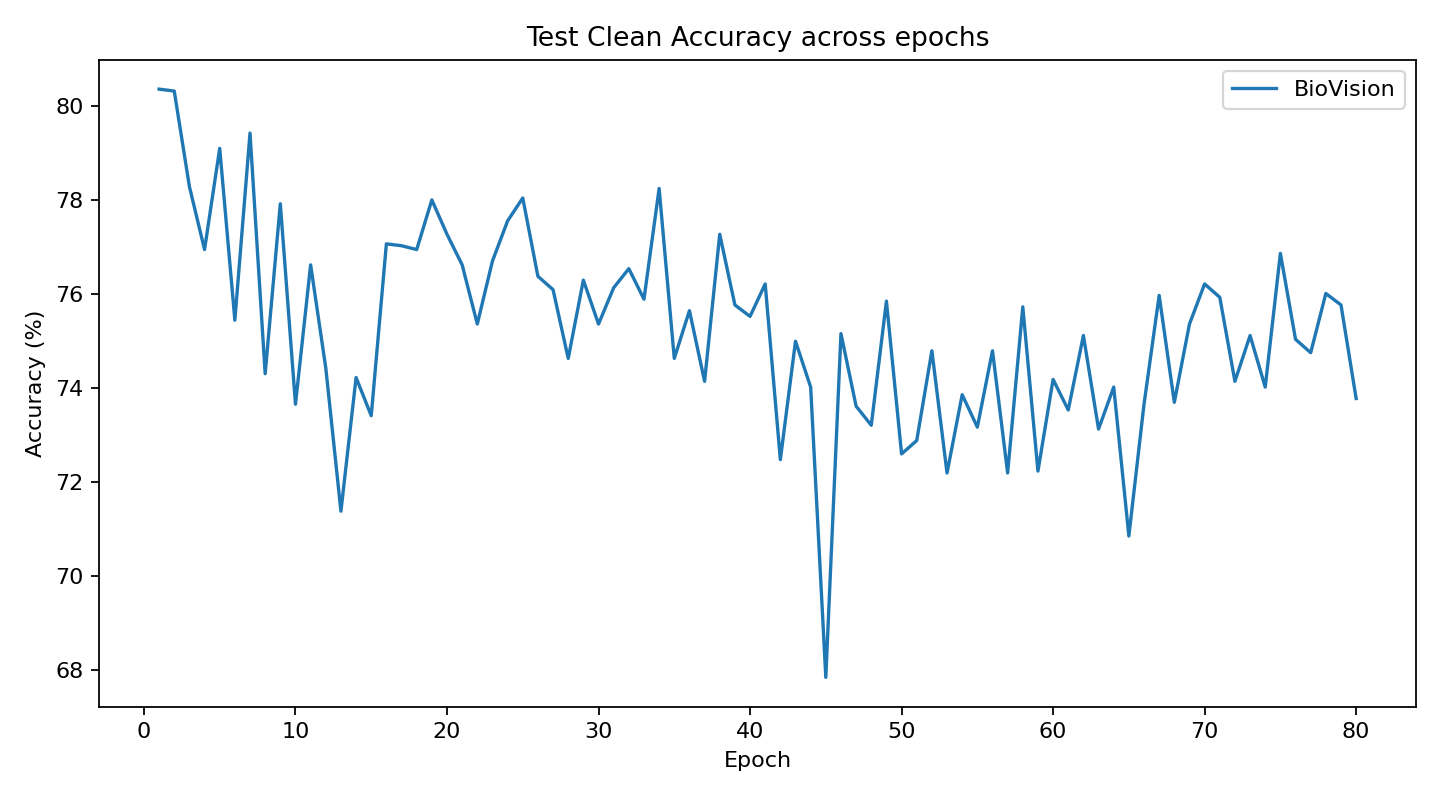
C6 - (0.51)Performance is more stable up to epoch 40. By lowering the clamp, P contributes earlier, correcting some of M´s early missteps.

C3 - (0.85) More “wild” fluctuations appear early on, reflecting delayed but forceful P interventions.

C6 - (0.51) Shows smoother performance from the start, as P participates more steadily in negotiations.
In practise, the clamp can be interpreted as a “participation threshold”.
The charts below illustrate how clamp values shape which pathway “wins” during disagreements.
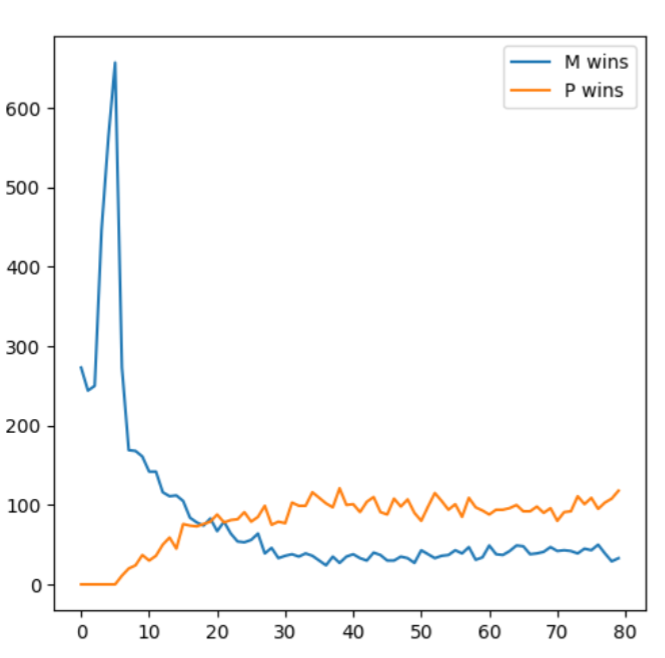
C3 High clamp (0.85) = P is cautious and joins late.

C6 Moderate clamp (0.51) = P is more liberal, joining disagreements early and frequently.
NEGOTIATION AS BLEND
Where clamp controls if and when P can step in, the blend parameter controls how much weight P and M carry when they disagree.
With blend = 0, the system behaves like a hard override: either M wins outright, or P wins outright when its confidence crosses the clamp.
With blend > 0, the final decision becomes a weighted combination of both pathways outputs.
Higher blend values mean P’s logits contribute more even when it doesn’t fully override.
Lower blend values keep M in stronger control, with P only nudging outcomes.
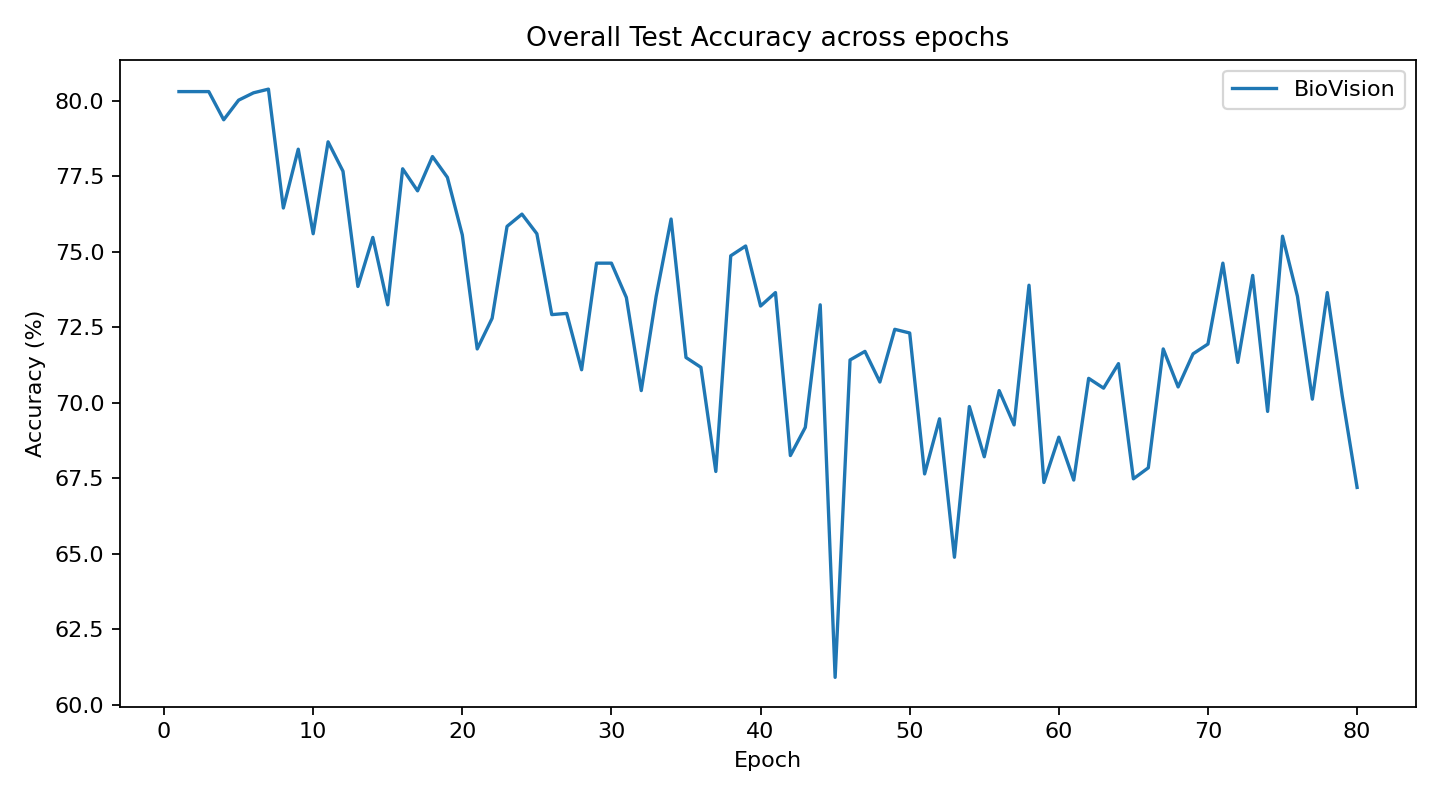
C9 Blend=0. Clear dominance of M, with P only occasionally shifting borderline cases.
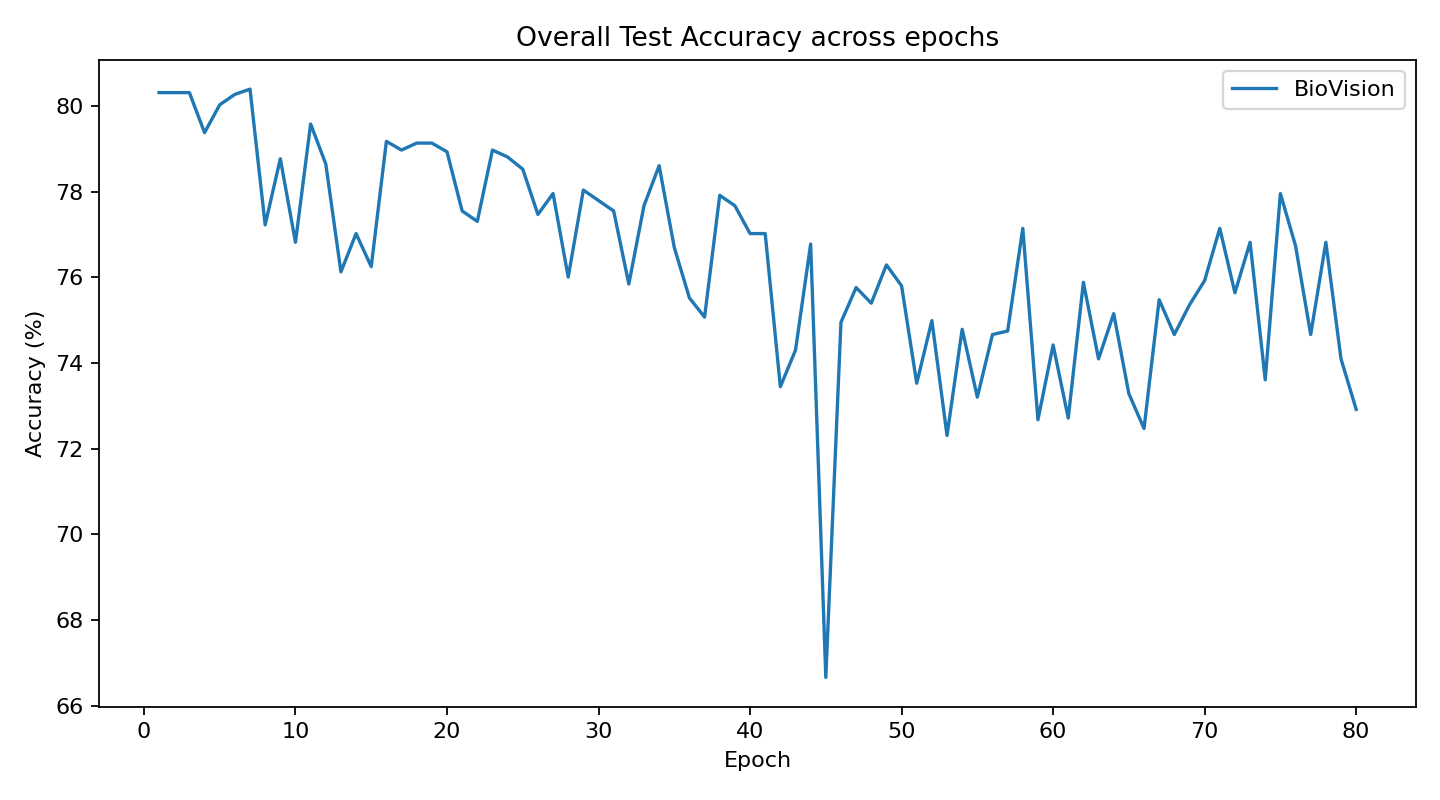
C11 Blend=0.95. Decisions are shared more evenly as P influences outcomes.
CONCLUSION : TIMING IS THE ARCHITECTURE OF VISION
Like mentioned before, Biovision was never created to “beat” standard CNN. Purpose was to test whether Collapse-Verify-Stamp could work as a code, and whether such timing dynamics would leave a measurable fingerprint.
There are far more to study and develop with the prototype, that involve both memories. However the results speak for themselves. Across repeated runs, with shifted thresholds, clamps and blends, the same negotiation patterns appear. Where verification is absent, instability reigns. Where verification participates, stability emerges. When verification learns from regret, the system becomes self-correcting.
It’s a structure, and maybe a fingerprint of perception itself, as a timing-based dual-path that is driven by negotiation.
The difference between traditional CNN that memorizes, Biovision might be taking the first steps at choosing. And in this way, it shows that perception is not about extracting data, but about committing to meaning.
FINAL WORDS
The framework of Visual Logic presented here, is the culmination of four years of private research and independent study, but in a way a longer life journey. The evolution of my thinking is documented in the earlier articles and blogs on this site, which trace the development of these ideas.
This theory, remains an open inquiry. As a personal investigation, addressing its core questions fully would require a collaborative effort, bridging the specialized silos of neurology, psychology, and computational science. Therefore, consider what you have read not as finished claim, but as an invitation.
Biggest unanswered question here remains with the nature of the Stamp.
The Ventral stream & Memory: Is ventral stream activation a crucial part for delivering experiences into long-term memory? Why does the parvocellular (P) pathway seem to hold this unique power?
Neurodiversity & Pathways: Could deficiencies or hyperactivity in these foundational pathways be a primary cause for larger-scale cognitive diversities? Or are they just the outcome? Perhaps, depending on the context, they can be either.
The Role of Mirroring: Where do mirror neurons fit into this logical sequence of perception and interpretation?
If future research end up providing evidence for this frame work, new immediate questions arise, particularly concerning illusions . Not as tricks, but as revelations.
Illusions: Are we tricking the brain, or is the brain revealing its blueprint.
Illusions may be the most crucial evidence of active construction in perception all along.
They can be simplified into two key categories:
Optical Illusions (Sensory mechanics)
What data is transmitted when we manipulate our sensory thresholds?
For example:
Staring a red dot for 30 seconds, when it gets removed we see “complementary” color - Cyan dot as an after image.
This happens because our receptors do not activate with light, but rather shut down. The longer and stronger the stimuli, the less responsive they become.
Once the red dot is removed, we will see what the two other active receptors can form. Green and blue = Cyan
But this happens effectively only if it the dot is removed against a white background, If you look at it against black, the less after image can form in your sight initially. As the video shows, it disappears momentarily when background “shuts down” as the sensory thresholds adapt.
Why?
Because with black, there is no stimuli for green and blue receptor either.
For the after image to appear clear, some stimuli needs to be involved within thresholds.
2. Imaginary Illusions (Contextual construction):
What happens when new context conflicts with learned experience?
For example:
We see two identical blocks as different sizes when placed within drawn perspective lines. A passive “prediction” model would suggest the brain guesses based on context, but then corrects itself upon learning the truth.
However, the illusion persists even after we consciously verify the blocks are identical. We can know they are the same, yet we cannot see them as the same as shown here.
Why? Because perception is not a single guess. It is continuous, frame-by-frame procedure. With each new moment of visual input, the brain collapses the data into a single actionable interpretation. And it always weights contextual cues (like perspective) extremely heavy. The conscious “knowledge” exists in a separate channel, but it cannot stop the perpetual machinery of construction from using context to build the visual world new.
This continuous reliance on context might prove that what we see is an active, on going translation of sensory data into a coherent world.
Context creates the outcome, based on the meaning of memorized and learned patterns from the prior visual experiences.
It could be that Illusions are not failures of perception, but revelations of its underlying logic.
For education, as I mentioned before, this site is filled with experiments and practical drawing simplifications based on my own experience, as I have developed new skillsets for myself thru science. From portraiture, to 3D by understanding visual phenomenon of reality. And the world is filled with such experiments.
ACKNOWLEDGMENTS
This investigation has been a quiet and lonesome journey thru these years.
Questioning myself, and my sanity has been the hardest part.
While this thesis might be nothing more than a private hallucination of my own, if even part of it proves true, then it will be something worth preserving.
For that reason, I take my time here with the few who deserve to have their names etched into this work.
While there are no institutions, funding or collaborations involved, the support and courage from few important people made this possible.
To my wife Tiina.
Thru the years, you have been the one to trust me. You have carried me, challenged me, and taught me to seek compromise without feeling loss. Above all, you pushed me forward to pursue what I sensed was there, even when I doubted it myself.
To my children: Miina, Ansa, Eino
You have been my force to move on. Watching you grow, your endless curiosity to create and play, your commitment to chase your dreams. Our sauna discussions.
Here, right now, I do not know who has been the teacher.
To my companion in business: Titta
We’ve built so many wild things together, always sharing the thrill and will to chase crazy ideas. None of this would exist without your trust.
To my friend: Repa
“Who can you argue with, if not a friend? With everyone else it is a waste of time.”
The endless arguments and debates from early evening to morning light, from history to daily news, sharpened me. For your fellowship on this journey, thru thick and thin, I thank you.
To Isto:
You listened my delusional early hypotheses and even brought your medical literacy to the table, helping me understand the brain’s messaging systems, where I finally placed the last pieces of the puzzle.
To Sampsa:
Right man in the right place at the right time. Sharing thoughts and the equipment you provided, let me sprint to the finish line.
To my friends:
For the unwavering fellowship thru this journey I would like to mention few:
Tapsa, Sami, Toni, Toni, Emil ja Mika.
And finally to my parents: Terhi, Jarmo
Though we had it rough, your love and pride in me never wavered, even in moments I might not have deserved it. It all worked out fine.
I love you all
This is my proof that even without a map, you can find a path.
Author:
Mikko Kiviranta